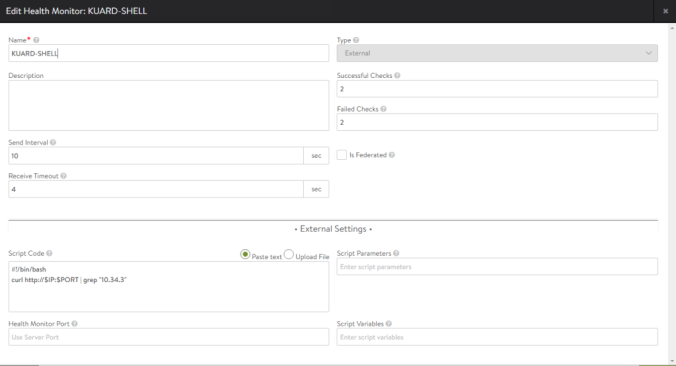
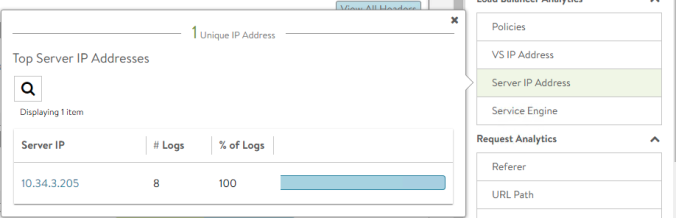
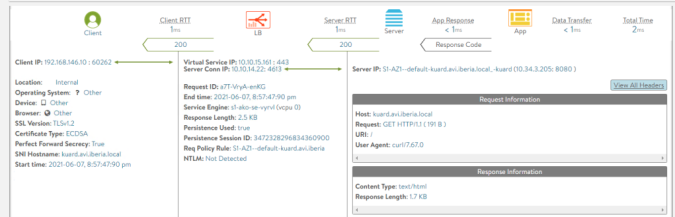
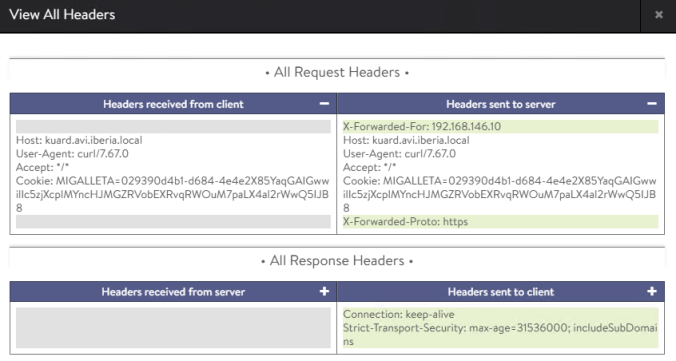
In the previous post we learnt how to install some important tools to provide observability including Grafana, Prometheus, Loki and Fluent-Bit.
Importing precreated Dashboards and Datasources in Grafana
The task of creating powerful data insights from metrics and logs through awesome visual dashboards is by far the most complex and time consuming task in the observability discipline. To avoid the creation of dashboard from scratch each time you deploy your observability stack, there is a method to import precreated dashboards very easily as long as someone already put the effort in creating your desired dashboard for you. A dashboard in Grafana is represented by a JSON object, which stores plenty of metadata including includes properties, size, placement, template variables, panel queries, etc.
If you remember from previous post here, we installed Grafana with datasource and dashboard sidecars enabled. As you can guess these sidecars are just auxiliary containers whose task is to watch for the existence of configmap in current namespace with a particular label. As soon as a new matching configmap appears the sidecars inject dynamically the extracted configuration and create a new datasource or dashboard.
I have created my own set of dashboards and datasources that you can reuse if you wish. To do so just clone the git repository as shown here.
Cloning into 'antrea'...
remote: Enumerating objects: 309, done.
remote: Counting objects: 100% (309/309), done.
remote: Compressing objects: 100% (182/182), done.
remote: Total 309 (delta 135), reused 282 (delta 109), pack-reused 0
Receiving objects: 100% (309/309), 1.05 MiB | 6.67 MiB/s, done.
Resolving deltas: 100% (135/135), done.First we will create the Datasources, so navigate to antrea/GRAFANA/datasources/ folder and list the content.
total 16
drwxrwxr-x 2 jhasensio 4096 Feb 27 18:48 .
drwxrwxr-x 4 jhasensio 4096 Feb 27 18:37 ..
-rw-rw-r-- 1 jhasensio 571 Feb 27 18:37 datasources.yamlIn this case, the Datasource is defined through a yaml file. The format is fully defined at official documentation here is very easy to identify the different fields as you can see below.
datasources:
datasources.yaml:
apiVersion: 1
datasources:
# Loki Datasource using distributed deployment (otherwise use port 3100)
- name: loki
type: loki
uid: loki
url: http://loki-gateway.loki.svc.cluster.local:80
access: proxy
version: 1
editable: false
# Prometheus Datasource marked as default
- name: prometheus
type: prometheus
uid: prometheus
url: http://prometheus-service.monitoring.svc.cluster.local:8080
access: proxy
isDefault: true
version: 1
editable: falseNow all that we need to do is to generate a configmap or a secret from the yaml file using kubectl create with –from-file keyword. Since the datasources might contain sensitive information is it better to use a secret instead of a configmap to leverage the encoding capabilities of the secret object. The following command will create a generic secret importing the data contained in the datasources.yaml all existing yaml files in current directory and will use the filename stripping .yaml extension as prefix for the configmaps names followed by -datasource-cm suffix.
secret/datasources-secret createdNext step is to label the secret object using the label and key we defined when we deployed Grafana.
secret/datasources-secret labeledNow we have to do a similar procedure with the dashboards. From the path where you cloned the git repo before, navigate to antrea/GRAFANA/dashboards/ and list the contents. You should see the json files that define the dashboards we want to import.
total 176
drwxrwxr-x 2 jhasensio 4096 Feb 27 18:37 .
drwxrwxr-x 4 jhasensio 4096 Feb 27 18:37 ..
-rw-rw-r-- 1 jhasensio 25936 Feb 27 18:37 1-agent-process-metrics.json
-rw-rw-r-- 1 jhasensio 28824 Feb 27 18:37 2-agent-ovs-metrics-and-logs.json
-rw-rw-r-- 1 jhasensio 15384 Feb 27 18:37 3-agent-conntrack-and-proxy-metrics.json
-rw-rw-r-- 1 jhasensio 39998 Feb 27 18:37 4-agent-network-policy-metrics-and-logs.json
-rw-rw-r-- 1 jhasensio 17667 Feb 27 18:37 5-antrea-agent-logs.json
-rw-rw-r-- 1 jhasensio 31910 Feb 27 18:37 6-controller-metrics-and-logs.jsonNow we will create the configmaps in the grafana namespace and label it. We can use a single-line command to do it recursively leveraging xargs command as shown below.
configmap/1-agent-process-metrics-dashboard-cm created
configmap/2-agent-ovs-metrics-and-logs-dashboard-cm created
configmap/3-agent-conntrack-and-proxy-metrics-dashboard-cm created
configmap/4-agent-network-policy-metrics-and-logs-dashboard-cm created
configmap/5-antrea-agent-logs-dashboard-cm created
configmap/6-controller-metrics-and-logs-dashboard-cm createdAnd now tag the created configmap objects using the label and key we defined when we deploy grafana using the command below.
configmap/1-agent-process-metrics-dashboard-cm labeled
configmap/2-agent-ovs-metrics-and-logs-dashboard-cm labeled
configmap/3-agent-conntrack-and-proxy-metrics-dashboard-cm labeled
configmap/4-agent-network-policy-metrics-and-logs-dashboard-cm labeled
configmap/5-antrea-agent-logs-dashboard-cm labeled
configmap/6-controller-metrics-and-logs-dashboard-cm labeledFeel free to explore the created configmaps and secrets to verify if they have proper labels before moving to Grafana UI using following command.
NAME DATA AGE LABELS
configmap/1-agent-process-metrics-dashboard-cm 1 5m32s grafana_dashboard=1
configmap/2-agent-ovs-metrics-and-logs-dashboard-cm 1 5m31s grafana_dashboard=1
configmap/3-agent-conntrack-and-proxy-metrics-dashboard-cm 1 5m31s grafana_dashboard=1
configmap/4-agent-network-policy-metrics-and-logs-dashboard-cm 1 5m31s grafana_dashboard=1
configmap/5-antrea-agent-logs-dashboard-cm 1 5m31s grafana_dashboard=1
configmap/6-controller-metrics-and-logs-dashboard-cm 1 5m31s grafana_dashboard=1
NAME TYPE DATA AGE LABELS
secret/datasources-secret Opaque 1 22m grafana_datasource=1If the sidecars did their job of watching for secrets with corresponding labels and importing their configuration into Grafana UI, we should now be able to access Grafana UI and see the imported datasources.

If you navigate to the Dashboards section you should now see the six imported dashboards as well.

Now we have imported the datasources and dashboards we can move into Grafana UI to explore the created visualizations, but before moving jumping to UI, lets dive a little bit into log processing to understand how the logs are properly formatted and pushed ultimately to Grafana dashboards.
Parsing logs with FluentBit
As we seen in previous post here, Fluent-bit is a powerful log shipper that can be used to push any log produced by Antrea components. The formatting or parsing is the process to extract useful information within the raw logs to achieve better understanding and filtering capabilites of the overall information. This might be a tough task that require some time and attention and understanding of how a regular expression work. The following sections will show how to obtain the desired log formatting configuration using a methodical approach.
1 Install FluentBit in a Linux box
The first step is to isntall fluent-bit. The quickest way is by using the provided shell script in the official page.
... skipped
Need to get 29.9 MB of archives.
After this operation, 12.8 MB of additional disk space will be used.
Get:1 https://packages.fluentbit.io/ubuntu/focal focal/main amd64 fluent-bit amd64 2.0.9 [29.9 MB]
Fetched 29.9 MB in 3s (8,626 kB/s)
(Reading database ... 117559 files and directories currently installed.)
Preparing to unpack .../fluent-bit_2.0.9_amd64.deb ...
Unpacking fluent-bit (2.0.9) over (2.0.6) ...
Setting up fluent-bit (2.0.9) ...
Installation completed. Happy Logging!Once the script is completed, the binary will be placed into the /opt/fluent-bit/bin path. Launch fluent-bit to check if is working. An output like the one shown below should be seen.
Fluent Bit v2.0.9
* Copyright (C) 2015-2022 The Fluent Bit Authors
* Fluent Bit is a CNCF sub-project under the umbrella of Fluentd
* https://fluentbit.io
[2023/03/13 19:15:50] [ info] [fluent bit] version=2.0.9, commit=, pid=1943703
...2 Obtain a sample of the target log
Next step is to get a sample log file of the intended system we want to process logs from. This sampe log will be used as the input for fluent-bit. As an example, let’s use the network policy log generated by Antrea Agent when enableLogging spec is set to true. Luckily, the log format is fully docummented here and we will use that as a base for our parser. We can easily identify some fields within the log line such as timestamp, RuleName, Action, SourceIP, SourcePort and so on.
2023/02/14 11:23:54.727335 AntreaPolicyIngressRule AntreaClusterNetworkPolicy:acnp-acme-allow FrontEnd_Rule Allow 14000 10.34.6.14 46868 10.34.6.5 8082 TCP 603 Create the the fluent-bit config file
Once we have a sample log file with targeted log entries create a fluent-bit.conf file that will be used to process our log file. In the INPUT section we are using the tail input plugin that will read the file specified in the path keyword below. After tail module read the file, the fluent-bit pipeline will send the data to the antreanetworkpolicy custom parser that we will create in next section. Last, the output section will send the result to the standard output (console).
[INPUT]
name tail
path /home/jhasensio/np.log
tag antreanetworkpolicy
read_from_head true
parser antreanetworkpolicy
path_key on
[OUTPUT]
Name stdout
Match *4 Create the parser
The parser is by far the most tricky part since you need to use regular expression to create matching patterns in order to extract the values for the desired fields according to the position of the values within the log entry. You can use rubular that is a great website to play with regular expressions and also provides an option to create a permalink to share the result of the parsing. I have created a permalink here that is also commented in the parser file below that can be used for this purpose to understand and play with regex using a sample log line as an input. The basic idea is to choose a name for the intended fields and use a regular expression to match with the log position that shows the value for that field. Note we end up with a pretty long regex expression to extract all the fields.
[PARSER]
Name antreanetworkpolicy
Format regex
# https://rubular.com/r/gCTJfLIkeioOgO
Regex ^(?<date>[^ ]+) (?<time>[^ ]+) (?<ovsTableName>[^ ]+) (?<antreaNativePolicyReference>[^ ]+) (?<rulename>[^ ]+) (?<action>[^( ]+) (?<openflowpriority>[^ ]+) (?<sourceip>[^ ]+) (?<sourceport>[^ ]+) (?<destinationip>[^ ]+) (?<destinationport>[^ ]+) (?<protocol>[^ ]+) (?<packetLength>.*)$4 Test filter and parser
Now that the config file and the parser are prepared, it is time to test the parser to check if is working as expected. Sometime you need to iterate over the parser configuration till you get the desired outcome. Use following command to test fluent-bit.
Fluent Bit v2.0.9
* Copyright (C) 2015-2022 The Fluent Bit Authors
* Fluent Bit is a CNCF sub-project under the umbrella of Fluentd
* https://fluentbit.io
[2023/03/13 19:26:01] [ info] Configuration:
[2023/03/13 19:26:01] [ info] flush time | 1.000000 seconds
[2023/03/13 19:26:01] [ info] grace | 5 seconds
... skipp
[2023/03/13 19:26:01] [ info] [output:stdout:stdout.0] worker #0 started
[0] antreanetworkpolicy: [1678731961.923762559, {"on"=>"/home/jhasensio/np.log", "date"=>"2023/02/14", "time"=>"11:23:54.727335", "ovsTableName"=>"AntreaPolicyIngressRule", "antreaNativePolicyReference"=>"AntreaClusterNetworkPolicy:acnp-acme-allow", "rulename"=>"FrontEnd_Rule", "action"=>"Allow", "openflowpriority"=>"14000", "sourceip"=>"10.34.6.14", "sourceport"=>"46868", "destinationip"=>"10.34.6.5", "destinationport"=>"8082", "protocol"=>"TCP", "packetLength"=>"60"}]
[2023/03/13 19:26:02] [debug] [task] created task=0x7f6835e4bbc0 id=0 OK
[2023/03/13 19:26:02] [debug] [output:stdout:stdout.1] task_id=0 assigned to thread #0
[2023/03/13 19:26:02] [debug] [out flush] cb_destroy coro_id=0
[2023/03/13 19:26:02] [debug] [task] destroy task=0x7f6835e4bbc0 (task_id=0)As you can see in the highlighted section the log entry has been sucessfully processed and a JSON document has been generated and sent to the console mapping the defined field names with the corresponding values matched in the log according to regex capturing process.
Repeat this procedure for all the different log formats that you plan to process until you get the desired results. Once done is time to push the configuration into kubernetes and run FluentBit as a daemonSet. The following values.yaml can be used to inject the fluent-bit configuration via Helm to process logs generated by Antrea controller, agents, openvSwitch and NetworkPolicy logs. Note that, apart from the regex, is also important to tag the logs with significant labels in order to get the most of the dashboards and achieve good filtering capabilities at Grafana.
# kind -- DaemonSet or Deployment
kind: DaemonSet
env:
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
config:
service: |
[SERVICE]
Daemon Off
Flush {{ .Values.flush }}
Log_Level {{ .Values.logLevel }}
Parsers_File parsers.conf
Parsers_File custom_parsers.conf
HTTP_Server On
HTTP_Listen 0.0.0.0
HTTP_Port {{ .Values.metricsPort }}
Health_Check On
## https://docs.fluentbit.io/manual/pipeline/inputs
inputs: |
[INPUT]
Name tail
Path /var/log/containers/antrea-agent*.log
Tag antreaagent
parser antrea
Mem_Buf_Limit 5MB
[INPUT]
Name tail
Path /var/log/containers/antrea-controller*.log
Tag antreacontroller
parser antrea
Mem_Buf_Limit 5MB
[INPUT]
Name tail
Path /var/log/antrea/networkpolicy/np*.log
Tag antreanetworkpolicy
parser antreanetworkpolicy
Mem_Buf_Limit 5MB
[INPUT]
Name tail
Path /var/log/antrea/openvswitch/ovs*.log
Tag ovs
parser ovs
Mem_Buf_Limit 5MB
## https://docs.fluentbit.io/manual/pipeline/filters
filters: |
[FILTER]
Name kubernetes
Match antrea
Merge_Log On
Keep_Log Off
K8S-Logging.Parser On
K8S-Logging.Exclude On
[FILTER]
Name record_modifier
Match *
Record podname ${HOSTNAME}
Record nodename ${NODE_NAME}
## https://docs.fluentbit.io/manual/pipeline/outputs
outputs: |
[OUTPUT]
Name loki
Match antreaagent
Host loki-gateway.loki.svc
Port 80
Labels job=fluentbit-antrea, agent_log_category=$category
Label_keys $log_level, $nodename
[OUTPUT]
Name loki
Match antreacontroller
Host loki-gateway.loki.svc
Port 80
Labels job=fluentbit-antrea-controller, controller_log_category=$category
Label_keys $log_level, $nodename
[OUTPUT]
Name loki
Match antreanetworkpolicy
Host loki-gateway.loki.svc
Port 80
Labels job=fluentbit-antrea-netpolicy
Label_keys $nodename, $action
[OUTPUT]
Name loki
Match ovs
Host loki-gateway.loki.svc
Port 80
Labels job=fluentbit-antrea-ovs
Label_keys $nodename, $ovs_log_level, $ovs_category
## https://docs.fluentbit.io/manual/pipeline/parsers
customParsers: |
[PARSER]
Name antrea
Format regex
# https://rubular.com/r/04kWAJU1E3e20U
Regex ^(?<timestamp>[^ ]+) (?<stream>stdout|stderr) (?<logtag>[^ ]*) ((?<log_level>[^ ]?)(?<code>\d\d\d\d)) (?<time>[^ ]+) (.*) ((?<category>.*)?(.go.*\])) (?<message>.*)$
[PARSER]
Name antreanetworkpolicy
Format regex
# https://rubular.com/r/gCTJfLIkeioOgO
Regex ^(?<date>[^ ]+) (?<time>[^ ]+) (?<ovsTableName>[^ ]+) (?<antreaNativePolicyReference>[^ ]+) (?<ruleName>[^ ]+) (?<action>[^( ]+) (?<openflowPriority>[^ ]+) (?<sourceIP>[^ ]+) (?<sourcePort>[^ ]+) (?<destinationIP>[^ ]+) (?<destinationPort>[^ ]+) (?<protocol>[^ ]+) (?<packetLength>.*)$
[PARSER]
Name ovs
Format regex
Regex ^((?<date>[^ ].*)\|(?<log_code>.*)\|(?<ovs_category>.*)\|(?<ovs_log_level>.*))\|(?<message>\w+\s.*$)Find a copy of values.yaml in my github here. Once your fluent-bit configuration is done, you can upgrade the fluent-bit release through helm using the following command to apply the new configuration.
Release "fluent-bit" has been upgraded. Happy Helming!
NAME: fluent-bit
LAST DEPLOYED: Tue Mar 14 17:27:23 2023
NAMESPACE: fluent-bit
STATUS: deployed
REVISION: 32
NOTES:
Get Fluent Bit build information by running these commands:
export POD_NAME=$(kubectl get pods --namespace fluent-bit -l "app.kubernetes.io/name=fluent-bit,app.kubernetes.io/instance=fluent-bit" -o jsonpath="{.items[0].metadata.name}")
kubectl --namespace fluent-bit port-forward $POD_NAME 2020:2020
curl http://127.0.0.1:202Exploring Dashboards
Now we understand how log shipping process work its time to jump into grafana to navigate through the different precreated dashboards that will represent not only prometheus metrics but also some will be helpful to explore logs and extract some metrics from them.
All the dashboards use variables that allow you to create more interactive and dynamic dashboards. Instead of hard-coding things like agent-name, instance or log-level, you can use variables in their place that are displayed as dropdown lists at the top of the dashboard. These dropdowns make it easy to filter the data being displayed in your dashboard.
Dashboard 1: Agent Process Metrics
The first dashboard provide a general view of observed kubernetes cluster. This dashboard can be used to understand some important metrics across the time such as CPU and memory usage, kubernetes API usage, filedescriptor and so on. I have tried to extract the most significative out of the full set of metrics as documented here but feel free to add extra metrics you are interested in.

Just to see graphs in action reacting to cluster conditions, lets play with CPU usage as an example. An easy way to impact CPU usage is by creating some activity in the cluster to stress CPU. Lets create a new deployment that will be used for this purpose with following command.
deployment.apps/www createdNow lets try to stress the antrea agent CPU a little bit by calling quite aggresively to the Kubernetes API. To do this we will use a loop to scale the deployment randomly to a number between 1 and 20 replicas and waiting a random number between 1 and 500 milliseconds between API calls.
deployment.apps/www scaled
deployment.apps/www scaled
deployment.apps/www scaled
deployment.apps/www scaled
... Stop with CTRL+CAs you can see as soon as we start to inject the CPU usage of the antrea agent running in the nodes is fairly impacted as the agent need to reprogram the ovs and plumb the new replica pods to the network.

On the other hand, the KubeAPI process is heavily impacted because is in charge to process all the API calls we are sending.

Another interesting panel is below and titld as Logs per Second. This panel uses all the logs received from the nodes via fluent-bit and received by Loki to calculate the logs per second rate. As soon as we scale in/out there is a lot of activity in the agents that is generating a big amount of logs. This can be useful as an indication of current cluster activity.

Explore other panels and play with variables such as instance to filter out the displayed information.
Dashboard 2: Agent OpenvSwitch (OVS) Metrics and Logs
The second dashboard will help us to understand what is happening behind the scenes in relation to the OpenvSwitch component. OpenvSwitch is an open source OpenFlow capable virtual switch used to create the SDN solution that will provide connectivity between the nodes and pods in this kubernetes scenario.
OpenvSwitch uses a Pipeline Model that is explained in the Antrea IO website here and is represented in the following diagram. (Note: It seems that the diagram is a little bit outdated since the actual Table IDs does not correspond to the IDs represented in official diagram).

The tables are used to store the flow information at different stages of the transit of the packet. As an example, lets take the SpoofGuardTable (correspond to TableID 1 in current implementation). The SpoofGuardTable which map to ID 1 is responsible for preventing IP and ARP spoofing from local Pods.
We can easily explore its content, for example, display the pods running on a given node (k8s-worker01)
jhasensio@forty-two:~/ANTREA$ kubectl get pod -A -o wide | grep -E "NAME|worker-01"
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
acme-fitness payment-5ffb9c8d65-g8qb2 1/1 Running 0 2d23h 10.34.6.179 k8s-worker-01 <none> <none>
fluent-bit fluent-bit-9n6nq 1/1 Running 2 (4d13h ago) 6d8h 10.34.6.140 k8s-worker-01 <none> <none>
kube-system antrea-agent-hbc86 2/2 Running 0 47h 10.113.2.15 k8s-worker-01 <none> <none>
kube-system coredns-6d4b75cb6d-mmscv 1/1 Running 2 (4d13h ago) 48d 10.34.6.9 k8s-worker-01 <none> <none>
kube-system coredns-6d4b75cb6d-sqg4z 1/1 Running 1 (20d ago) 48d 10.34.6.7 k8s-worker-01 <none> <none>
kube-system kube-proxy-fvqbr 1/1 Running 1 (20d ago) 48d 10.113.2.15 k8s-worker-01 <none> <none>
load-gen locust-master-67bdb5dbd4-ngtw7 1/1 Running 0 2d22h 10.34.6.184 k8s-worker-01 <none> <none>
load-gen locust-worker-6c5f87b5c8-pgzng 1/1 Running 0 2d22h 10.34.6.185 k8s-worker-01 <none> <none>
logs logs-pool-0-4 1/1 Running 0 6d18h 10.34.6.20 k8s-worker-01 <none> <none>
loki loki-canary-7kf7l 1/1 Running 0 15h 10.34.6.213 k8s-worker-01 <none> <none>
loki loki-logs-drhbm 2/2 Running 0 6d18h 10.34.6.22 k8s-worker-01 <none> <none>
loki loki-read-2 1/1 Running 0 6d9h 10.34.6.139 k8s-worker-01 <none> <none>
loki loki-write-1 1/1 Running 0 15h 10.34.6.212 k8s-worker-01 <none> <none>
minio-operator minio-operator-868fc4755d-q42nc 1/1 Running 1 (20d ago) 35d 10.34.6.3 k8s-worker-01 <none> <none>
vmware-system-csi vsphere-csi-node-42d8j 3/3 Running 7 (18d ago) 35d 10.113.2.15 k8s-worker-01 <none> <none>Take the Antrea Agent pod name and dump the content of the SpoofGuardTable of the OVS container in that particular Node by issuing the following command.
cookie=0x7010000000000, table=1, priority=200,arp,in_port=2,arp_spa=10.34.6.1,arp_sha=12:2a:4a:31:e2:43 actions=resubmit(,2)
cookie=0x7010000000000, table=1, priority=200,arp,in_port=10,arp_spa=10.34.6.9,arp_sha=16:6d:5b:d2:e6:86 actions=resubmit(,2)
cookie=0x7010000000000, table=1, priority=200,arp,in_port=183,arp_spa=10.34.6.185,arp_sha=d6:c2:ae:76:9d:25 actions=resubmit(,2)
cookie=0x7010000000000, table=1, priority=200,arp,in_port=140,arp_spa=10.34.6.140,arp_sha=4e:b4:15:50:90:3e actions=resubmit(,2)
cookie=0x7010000000000, table=1, priority=200,arp,in_port=139,arp_spa=10.34.6.139,arp_sha=c2:07:8f:35:8b:17 actions=resubmit(,2)
cookie=0x7010000000000, table=1, priority=200,arp,in_port=4,arp_spa=10.34.6.3,arp_sha=7a:d9:fd:e7:2d:af actions=resubmit(,2)
cookie=0x7010000000000, table=1, priority=200,arp,in_port=182,arp_spa=10.34.6.184,arp_sha=7a:5e:26:ef:76:07 actions=resubmit(,2)
cookie=0x7010000000000, table=1, priority=200,arp,in_port=21,arp_spa=10.34.6.20,arp_sha=fa:e6:b9:f4:b1:e7 actions=resubmit(,2)
cookie=0x7010000000000, table=1, priority=200,arp,in_port=23,arp_spa=10.34.6.22,arp_sha=3a:17:f0:79:49:24 actions=resubmit(,2)
cookie=0x7010000000000, table=1, priority=200,arp,in_port=177,arp_spa=10.34.6.179,arp_sha=92:76:e0:a4:f4:57 actions=resubmit(,2)
cookie=0x7010000000000, table=1, priority=200,arp,in_port=8,arp_spa=10.34.6.7,arp_sha=8e:cc:4d:06:80:ed actions=resubmit(,2)
cookie=0x7010000000000, table=1, priority=200,arp,in_port=210,arp_spa=10.34.6.212,arp_sha=7e:34:08:3d:86:c5 actions=resubmit(,2)
cookie=0x7010000000000, table=1, priority=200,arp,in_port=211,arp_spa=10.34.6.213,arp_sha=9a:a8:84:d5:74:70 actions=resubmit(,2)
cookie=0x7000000000000, table=1, priority=0 actions=resubmit(,2)This SpoofGuard table contains the port of the pod, the IP address and the associated MAC and is automatically populated upon pod creation. The OVS metrics are labeled by table ID so its easy to identify the counters for any given identifier. Using the filter variable at the top of the screen select the ovs_table 1. As you can see from the graph the value for each of the table remains steady which mean there has not been recent pod creation/deletion activity in the cluster in the interval of observation. Also you can see how the value is almost the same in all the worker nodes which means the pods are evenly distributed across the worker. As expected the control plane node has less fewer entries.

Again, as we want to see dashboards in action, we can generate some counter variations easily scaling in/out a deployment. Using the www deployment we created before, scale now to 100 replicas. The pods should be scheduled among the worker nodes and the Table 1 will be populated with corresponding entries. Lets give a try.
deployment.apps/www scaledThe counter for this particular table now increases rapidly and the visualization graph shows now updated values.

Similarly, there is another ovs table which is the EndpointDNAT (Table11) that program DNAT rules to reach endpoints behind a clusterIP service. Using the variable filters at the top of the dashboard select ovs_table 1 and 11 in the same graph and select only the instance k8s-worker-01. Note how the EndpointDNAT (11) hasn’t change at all during the scale out process and has remained steady at the value 101 in this particular case.

If you expose now the deployment under test, all the pod replicas will be used as endpoints which means the overall endpoints should be incremented by exactly one hundred.
service/www exposedNow the www service should have 100 endpoints as showed below and correspondindly, the counter of the Table11 which contains the information to reach the endpoints of the cluster will be also incremented by the same amount.
NAME ENDPOINTS AGE
www 10.34.1.59:28888,10.34.1.60:28888,10.34.1.61:28888 + 97 more... 47sYou can check in any of the antrea agent container the entries that the creation of the service has created using the following ovs command line at the antrea-ovs container.
cookie=0x7030000000000, table=11, priority=200,tcp,reg3=0xa22049a,reg4=0x270d8/0x7ffff actions=ct(commit,table=12,zone=65520,nat(dst=10.34.4.154:28888),exec(load:0x1->NXM_NX_CT_MARK[4],move:NXM_NX_REG0[0..3]->NXM_NX_CT_MARK[0..3]))
cookie=0x7030000000000, table=11, priority=200,tcp,reg3=0xa2202da,reg4=0x270d8/0x7ffff actions=ct(commit,table=12,zone=65520,nat(dst=10.34.2.218:28888),exec(load:0x1->NXM_NX_CT_MARK[4],move:NXM_NX_REG0[0..3]->NXM_NX_CT_MARK[0..3]))
cookie=0x7030000000000, table=11, priority=200,tcp,reg3=0xa22013c,reg4=0x270d8/0x7ffff actions=ct(commit,table=12,zone=65520,nat(dst=10.34.1.60:28888),exec(load:0x1->NXM_NX_CT_MARK[4],move:NXM_NX_REG0[0..3]->NXM_NX_CT_MARK[0..3]))
... skippedAnd consequently the graph shows the increment by 100 endpoints that correspond to the ClusterIP www service exposition backed by the 100-replica deployment we created.

Note also how this particular table 11 in charge of Endpoints is synced accross all the nodes because every pod in the cluster should be able to reach any of the endpoints through the clusterIP service. This can be verified changing to All instances and displaying only the ovs_table11. All the nodes in the cluster shows the same value for this particular table.

These are just two examples of tables that are automatically programmed and might be useful to visualize the entries of the OVS switch. Feel free to explore any other panels playing with filters within this dashboard.
As a bonus, you can see at the bottom of the dashboard there is a particular panel that shows the OVS logs. Having all the logs from all the workers in a single place is a great advantage for troubleshooting.
The logs can be filtered out using the instance, ovs_log_level and ovs_category variables at the top of the dashboard. The filters might be very useful to focus only on the relevant information we want to display. Note that, by default, the log level of the OVS container is set to INFO, however, you can increase the log level for debugging purposes to get higher verbosity. (Note: As with any other logging subsystem, increasing log level to DEBUG can adversely impact performance so be careful). To check the current status of the logs
console syslog file
------- ------ ------
backtrace OFF ERR INFO
bfd OFF ERR INFO
bond OFF ERR INFO
bridge OFF ERR INFO
bundle OFF ERR INFO
bundles OFF ERR INFO
cfm OFF ERR INFO
collectors OFF ERR INFO
command_line OFF ERR INFO
connmgr OFF ERR INFO
conntrack OFF ERR DBG
conntrack_tp OFF ERR INFO
coverage OFF ERR INFO
ct_dpif OFF ERR INFO
daemon OFF ERR INFO
... <skipped>
vlog OFF ERR INFO
vswitchd OFF ERR INFO
xenserver OFF ERR INFOIf you want to increase the error level in any of the categories use following command ovs-appctl command. The syntax of the command specifies the subsystem, the log target (console, file or syslog) and the log level where dbg is the maximum level and info is the default for the file logging. As you can guess dbg must be enabled only during a troubleshooting session and disabled afterwards to avoid performance issues. This command is applied only to an specified agent. To restore the configuration of all the subsystems just use the keyworkd ANY instead of specifying a subsystem.
kubectl exec -n kube-system antrea-agent-hbc86 -c antrea-ovs -- ovs-appctl vlog/set dpif:file:infoIf you want to repeat and change in all the agents accross the cluster use the following command to add recursiveness through xargs command.
kubectl get pods -n kube-system | grep antrea-agent | awk '{print $1}' | xargs -n1 -I{arg} kubectl exec -n kube-system {arg} -c antrea-ovs -- ovs-appctl vlog/set dpif:file:dbgGo back to the grafana dashboard and explore some of the entries. As an example the creation of a new pod produces the following log output. As mentioned earlier in this post, the original message has been parsed by FluentBit to extract the relevant fields and is formatted by Grafana to gain some human readability.

Dashboard 3: Agent Conntrack and Proxy Metrics
The next dashboard is the conntrack and is helpful to identify the current sessions and therefore the actual activity in terms of traffic in the cluster. Conntrack is part of every Linux stack and allows the kernel to track all the network connections (a.k.a flows) in order to identify all the packets that belong to a particular flow and provide a consistent treatment. This is useful for allowing or denying packets as part of a stateful firewall subsystem and also for some network translations mechanisms that require this connection tracking to work properly.
The conntrack table has its a maximum size and is important to monitor that the limits are not surpassed to avoid issues. Lets use the traffic generator we installed in the previous post to see how the metrics reacts to new traffic coming into the system. Access the Dashboard Number 3 in Grafana UI. The Conntrack section shows the number of entries (namely connections or flows) in the conntrack table. The second panel calculates the percentage of flows using the Prometheus antrea_agent_conntrack_max_connection_track metric and is useful to monitor how close we are to the limit of the node in terms of established connections.

To play around with this metric lets inject some traffic using the Load Generator tool we installed in previous post here. Open the Load Generator and inject some traffic by clicking on New Test and select 5000 users with a spawn rate of 100 users/second and http://frontend.acme-fitness.svc as target endpoint to sent our traffic to. Next, click Start swarming button.

After some time we can see how we have reached a fair number of request per second and there are no failures.

Narrow the dispaly interval at the right top corner to show the last 5 or 15 minutes and, after a while you can see how the traffic injection produces a change in the number of connections.

The Conntrack percentage also follow the same pattern and show a noticeable increase.

The Percentage is still far from the limit. Let’s push a little bit more simulating a L4 DDoS attack in next section.
Detecting a L4 DDoS attack
To push the networking conntrack stack to the limit, let’s attempt a L4 DDoS attack using the popular hping3 tool. This tool can be useful to generate a big amount of traffic against a target (namely victim) system. We will run it in kubernetes as a deployment to be able to scale in/out to inject even more traffic to see if we can reach the limits of the system. The following manifest will be used to spin up the ddos-atacker pods. Modify the variables to match with the target you want to try. The below ddos-attacker.yaml file will instruct kubernetes to spin up a single replica deployment that will inject traffic to our acme-fitness frontend application listening at port 80. The hping3 command will flood as much TCP_SYN segments as it can send without waiting for confirmation.
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: ddos-attacker
name: ddos-attacker
spec:
replicas: 1
selector:
matchLabels:
app: ddos-attacker
template:
metadata:
labels:
app: ddos-attacker
spec:
containers:
- image: sflow/hping3
name: hping3
env:
# Set TARGET_HOST/TARGET_PORT variables to your intended target
# For Pod use pod-ip-address.namespace.pod.cluster-domain.local
# Example: 10-34-4-65.acme-fitness.pod.cluster.local
# For svc use svc_name.namespace.svc.cluster.local
# Example : frontend.acme-fitness.svc.cluster.local
# Flood Mode, use with caution!
- name: TARGET_HOST
value: "frontend.acme-fitness.svc.cluster.local"
#value: "10-34-1-13.acme-fitness.pod.cluster.local"
- name: TARGET_PORT
# if pod use port 3000, if svc, then 80
value: "80"
# -S --flood initiates DDoS SYN Flooding attack
command: ["/usr/sbin/hping3"]
args: [$(TARGET_HOST), "-p", $(TARGET_PORT), "-S", "--flood"]Once the manifest is applied the deployment will spin up a single replica. Hovering at the graphic of the top panel you can see the number of connections generated by the hping3 execution. As you can see there are two workers that shows a count at around 70K connections. The hping3 will be able to generate up to 65K connections as per TCP limitations. As you can see below, the panel at the top shows an increase in the connections in two of the workers.

As you can guess, these two affected workers must have something to do with the attacker and the victim pods. You can easily verify where are both of them currently scheduled using the command below that in fact, frontend pod (victim) is running on k8s-worker-02 node whereas ddos-attacker pod is running on k8s-worker-06 which makes senses according to the observed behaviour.
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
acme-fitness frontend-6cd56445-bv5vf 1/1 Running 0 55m 10.34.2.180 k8s-worker-02 <none> <none>
default ddos-attacker-6f4688cffd-9rxdf 1/1 Running 0 2m36s 10.34.1.175 k8s-worker-06 <none> <none>Additionaly, the panel below shows the Conntrack connections percentage. Hovering the mouse over the graph you can display a table with actual values for all the measurements represnted in the graphic. The two workers involved in the attack are reaching an usage of 22% of the total available connections.

Now scale the ddos deployment to spin up more replicas. Adjust the replica count according to your cluster size. In my case I am using a 6-worker cluster so I will scale out to 5 replicas that will be more than enough.
deployment.apps/ddos-attacker scaledThe graph now show how the count usage reach the 100% in k8s-worker-02 that is the node where the victim is running on. The amount of traffic sent to the pod is likely to cause a denial of service since the Antrea Conntrack table will have issues to accomodate new incoming connections.

The number of connections (panel at the top of the dashboards) shows an overall of +500K connections at node k8s-worker-02 which exceeds the maximum configured conntrack table.

As you can imagine, the DDoS attack is also impacting the CPU usage at each of the antrea-agent process. If you go back to dashboard 1 you can check how CPU usage is heavily impacted with values peaking at 150% of CPU usage and how the k8s-worker-02 node is specially struggling during the attack.

Now stop the attack and wide the display vistualization interval to visualize 6 hours range. If you look retrospectively is easy to identify the ocurrence of the DDoS attacks attemps in the timeline.

Dashboard 4: Network Policy and Logs
The next dashboard is related with Network Policies and is used to understand what is going on in this topic by means of the related metrics and logs. If there are no policies at all in your cluster you will see a boring dashboard like the one below showing the idle state.

As docummented in the Antrea.io website, Antrea supports not only standard K8s NetworkPolicies to secure ingress/egress traffic for Pods but also adds some extra CRDs to provide the administrator with more control over security within the cluster. Using the acme-fitness application we installed in previous post we will play with some policies to see how they are reflected in our grafana dashboard. Lets create firstly an Allow ClusterNetworkPolicy to control traffic going from frontend to catalog microservice that are part of the acme-fitness application under test. See comments in the yaml for further explanation
apiVersion: crd.antrea.io/v1alpha1
kind: ClusterNetworkPolicy
metadata:
name: acnp-acme-allow
spec:
# The policy with the highest precedence (the smallest numeric priority value) is enforced first.
priority: 10
# Application Tier
tier: application
# Enforced at pods matching service=catalog at namespace acme-fitness
appliedTo:
- podSelector:
matchLabels:
service: catalog
namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: acme-fitness
# Application Direction. Traffic coming from frontend pod at acme-fitness ns
ingress:
- action: Allow
from:
- podSelector:
matchLabels:
service: frontend
namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: acme-fitness
# Application listening at TCP 8082
ports:
- protocol: TCP
port: 8082
name: Allow-From-FrontEnd
# Rule hits will be logged in the worker
enableLogging: trueOnce you apply the above yaml you can verify the new Antrea Cluster Network Policy (in short acnp).
NAME TIER PRIORITY DESIRED NODES CURRENT NODES AGE
acnp-acme-allow application 10 1 1 22sReturn to the cluster and you will see some changes showing up.

Note the policy is calculated and effective only in the worker where the appliedTo matching pods actually exist. In this case the catalog pod lives on the k8s-worker-01 as reflected in the dasboard and verified by the output shown below.
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
catalog-958b9dc7c-brljn 1/1 Running 2 (42m ago) 60m 10.34.6.182 k8s-worker-01 <none> <none>If you scale the catalog deployment, then the pods will be scheduled accross more nodes in the cluster and the networkpolicy will be enforced in multiple nodes.
deployment.apps/catalog scaledNote how, after scaling, the controller recalculates the network policy and it pushed it to 6 of the nodes.
NAME TIER PRIORITY DESIRED NODES CURRENT NODES AGE
acnp-acme-allow application 10 6 6 6m46sThis can be seen in the dashboard as well. Now use the locust tool mentioned earlier to inject some traffic to see network policy hits.

Now change the policy to deny the traffic using Reject action using the following manifest.
apiVersion: crd.antrea.io/v1alpha1
kind: ClusterNetworkPolicy
metadata:
name: acnp-acme-reject
spec:
# The policy with the highest precedence (the smallest numeric priority value) is enforced first.
priority: 10
# Application Tier
tier: application
# Enforced at pods matching service=catalog at namespace acme-fitness
appliedTo:
- podSelector:
matchLabels:
service: catalog
namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: acme-fitness
# Application Direction. Traffic coming from frontend pod at acme-fitness ns
ingress:
- action: Reject
from:
- podSelector:
matchLabels:
service: frontend
namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: acme-fitness
# Application listening at TCP 8082
ports:
- protocol: TCP
port: 8082
name: Reject-from-Frontend
# Rule hits will be logged in the worker
enableLogging: trueThe Reject action will take precedence over the existing ACNP with Allow action and the hit counter begin to increment progressively.

Feel free to try with egress direction and with drop action to see how the values are populated. A little bit below, you can find a panel with the formatted log entries that are being pushed to Loki by fluent-bit. Expand any entry to see all the fields and values.

You can use the filters at the top of the dashboard to filter using source or destination IP. You can enter the whole IP or just a some octect since the matching is done using a regex to find the at any part of the IPv4. As an example, the following filter will display logs and logs derived metric where the source IP contains .180 and the destination IP contains .85.

Once the data is entered all the logs are filtered to display only matching entries. This not only affect to the Log Analysis panel but also to the rest of panels derived from the logs and can be useful to drill down and focus only on desired conversations within the cluster.

Last but not least, there are two more sections that analyze the received logs and extract some interesting metrics such as Top DestinationIP, Top SourceIPs, Top Converstion, Top Hits by rule and so on. These analytics can be useful to identify most top talkers in the cluster as well as identifying traffic that might be accidentaly denied. Remember this analytics are also affected by the src/dst filters mentioned above.

Dashboard 5: Antrea Agent Logs
Next dashboard is the Antrea Agent Logs. This dashboard is purely generated from the logs that the Antrea Agent produces at each of the k8s nodes. All the panels can be filtered out using the variables like the log level and the log_category to obtain the desired set of logs and avoid other noisy and less relevant logs.

As an example lets see the trace left by Antrea when a new node is scheduled in a worker node. First use the log_category filter to select pod_configuration and server subsystems only. Next use following command to create a new 2-replica deployment using apache2 image.
deployment.apps/www createdNote how the new deployment has produced some logs in the pod_configuration and server log categorie subsystem specifically in k8s-worker-01 and k8s-worker-02

Verify the pods has been actually scheduled in k8s-worker-01 and k8s-worker-02
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
www-86d9694b49-m85xl 1/1 Running 0 5m26s 10.34.2.94 k8s-worker-02 <none> <none>
www-86d9694b49-r6kwq 1/1 Running 0 5m26s 10.34.6.187 k8s-worker-01 <none> <none>The logs panel shows the activity created when the kubelet request IP connectivity to the new pod (CmdAdd).

If you need to go deeper in the logs there’s always an option to increase the log verbosity. By default the log is set to the minimum or zero.
0
0
0
0
0
0
0But, for troubleshooting or research purposes you can change log level to 4 which is the maximum verbosity. You can do it using following single-line command in all the nodes in the cluster.
kubectl get pods -n kube-system | grep antrea-agent | awk '{print $1}' | xargs -n1 -I{arg} kubectl exec -n kube-system {arg} -c antrea-agent -- antctl log-level 4Note the command is executed silently, so repeat previous command without the log-level keyword to check if the new settings has been applied and you should receive an output of 4 in each of iterations. Now delete the previous www deployment and recreate it again. As you can see in the Antrea Logs panel the same operation now produces much more logs with enriched information.

Increasing the log level can be useful to see conntrack information. If you are interested in flow information, increasing the log verbosity temporarily might be a good option. Lets give a try. Expose the previous www deployment using below command.
service/www exposedAnd now create a new curl pod to generate some traffic towards the created service to see if to locate the conntrack flows.
If you don't see a command prompt, try pressing enter.
/ $ / $ curl www.default.svc
<html><body><h1>It works!</h1></body></html>Using the log_category filter at the top select the conntrack_connections to focus only on flow relevant logs.

For further investigation you can click on the arrow next to the Panel Title and then click on Explore to drill down.

Change the query and add filter to get only logs containing “mycurlpod” and “DestionationPort:80” which corresponds with the flow we are looking for.

And you will get the log entries matching the search filter entered as shown in the following screen.

You can copy the raw log entry for further analysis or forensic / reporting purposes. Its quite easy to identigy Source/Destination IP Addresses, ports and other interesting metadata such as matching ingress and egress security policies affecting this particular traffic.
FlowKey:{SourceAddress:10.34.6.190 DestinationAddress:10.34.2.97 Protocol:6 SourcePort:46624 DestinationPort:80} OriginalPackets:6 OriginalBytes:403 SourcePodNamespace:default SourcePodName:mycurlpod DestinationPodNamespace: DestinationPodName: DestinationServicePortName:default/www: DestinationServiceAddress:10.109.122.40 DestinationServicePort:80 IngressNetworkPolicyName: IngressNetworkPolicyNamespace: IngressNetworkPolicyType:0 IngressNetworkPolicyRuleName: IngressNetworkPolicyRuleAction:0 EgressNetworkPolicyName: EgressNetworkPolicyNamespace: EgressNetworkPolicyType:0 EgressNetworkPolicyRuleName: EgressNetworkPolicyRuleAction:0 PrevPackets:0 PrevBytes:0 ReversePackets:4 ReverseBytes:486 PrevReversePackets:0 PrevReverseBytes:0 TCPState:TIME_WAIT PrevTCPState:}Once your investigation is done, do not forget to restore the log level to zero to contain the log generation using following filter.
kubectl get pods -n kube-system | grep antrea-agent | awk '{print $1}' | xargs -n1 -I{arg} kubectl exec -n kube-system {arg} -c antrea-agent -- antctl log-level 0These are just a couple of examples to explore the logs sent by Fluent-Bit shipper in each of the workers. Feel free to explore the dashboards using the embedded filters to see how affect to the displayed information.
Dashboard 6: Antrea Controller Logs
The dashboard 6 displays the activity related to Controller component of Antrea. The controller main function at this moment is to take care of NetworkPolicy implementation. For that reason unless there is networkpolicy changes you won’t see any log or metric expect the Controller Process CPU Seconds which should remain very low (under 2% of usage).

If you want to see some metrics in action you can generate some activity just by pushing some networkpolicies. As an example create a manifest to create cluster network policies and networkpolicies.
apiVersion: crd.antrea.io/v1alpha1
kind: ClusterNetworkPolicy
metadata:
name: test-acnp
namespace: acme-fitness
spec:
priority: 10
tier: application
appliedTo:
- podSelector:
matchLabels:
service: catalog
ingress:
- action: Reject
from:
- podSelector:
matchLabels:
service: frontend
ports:
- protocol: TCP
port: 8082
name: AllowFromFrontend
enableLogging: false
---
apiVersion: crd.antrea.io/v1alpha1
kind: NetworkPolicy
metadata:
name: test-np
namespace: acme-fitness
spec:
priority: 3
tier: application
appliedTo:
- podSelector:
matchLabels:
service: catalog
ingress:
- action: Allow
from:
- podSelector:
matchLabels:
service: frontend
ports:
- protocol: TCP
port: 8082
name: AllowFromFrontend
enableLogging: trueUsing a simple loop like the one below, create and delete recursively the same policy waiting a random number of time between iterations
clusternetworkpolicy.crd.antrea.io/test-acnp created
networkpolicy.crd.antrea.io/test-np created
clusternetworkpolicy.crd.antrea.io "test-acnp" deleted
networkpolicy.crd.antrea.io "test-np" deleted
clusternetworkpolicy.crd.antrea.io/test-acnp created
networkpolicy.crd.antrea.io/test-np created
clusternetworkpolicy.crd.antrea.io "test-acnp" deleted
networkpolicy.crd.antrea.io "test-np" deletedKeep the loop running for several minutes and return to grafana UI to check how the panels are populated.

As in the other dashboards, at the bottom you can find the related logs that are being generated by the network policy creation / deletion activity pushed to the cluster.

Stop the loop by pressing CTRL C. As in the others systems generating logs, you can increase the log level by using the same method mentioned earlier. You can try to configure the antrea controller to the maximum verbosity which is 4.
kubectl exec -n kube-system antrea-controller-74799d4774-g6cxt -c antrea-controller -- antctl log-level 4Repeat the same loop and you will find a dramatic increase in number of messages being logged. At the Logs Per Second Panel at the upper right corner you can notice an increasing in the logs per second rate from 6 to a steady rate of +120 logs per second.

When finished do not forget to restore log level to 0
kubectl exec -n kube-system antrea-controller-74799d4774-g6cxt -c antrea-controller -- antctl log-level 0This concludes this series of Observability on Antrea. I hope it has served to shed light on a crucial component in any Kubernetes cluster such as the CNI and that it allows not only to properly understand the operation from the perspective of networks, but also to enhance the capabilities of analysis and troubleshooting.