Now is time to make our architecture even more robust by leveraging the GSLB capabilities of AVI. We will create distributed DNS model in which the GSLB objects are distributed and synced across the different sites. The neutral DNS site will remain as the Leader but we will use the other AVI Controllers already in place to help service DNS requests as well as to provide extra availability to the whole architecture.

Define GSLB Followers
To allow the other AVI Controllers to take part in DNS resolution (in terms of GSLB feature to turn the AVI Controllers into Active members), a DNS Virtual service must be also defined in the same way. Remember in AVI Controller at Site1 we defined two separate VRFs to acomodate the two different k8s clusters. For consistency we used also an independent VRF for Site2 even when it was not a requirement since we were handling a single k8s cluster. Do not fall into the temptation to reuse one of the existing VRFs to create the DNS Virtual Service we will use for GSLB Services!! Remember AMKO will create automatically Health-Monitors to verify the status of the Virtual Services so it can ensure reachability before answering DNS queries. If we place the Virtual Service in one of the VRFs, the Health-Monitor would not be able to reach the services in the other VRF because they have isolated routing tables. When a VRF has been used by the AKO integration the system will not allow you to define static IP routes in that VRF to implement a kind of route-leaking to reach other VRFs. This constraint would cause the GSLB related Health-Monitors in that VRF to be unable to reach services external to the VRF, therefore any service outside will be declared as DOWN. The solution is to place the DNS VS in the global VRF and define a default gateway as per your particular network topology.

Define a new network of your choice for IPAM and DNS VS and SE placement. In my case I have selected 10.10.22.0/24.


Repeat the same process for the Site2. In this case I will use the network 10.10.21.0/24. The resulting DNS VS configuration is shown below
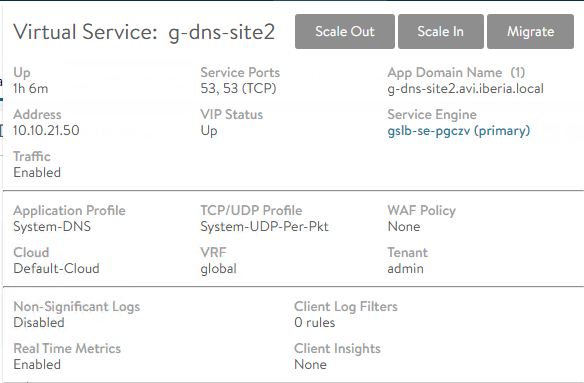
Last step is the IP routing configuration to allow Health-Monitors to reach the target VS they need to monitor. Till now we haven’t defined IP routing information for the Virtual Services. The Virtual Service just return the traffic for the incoming requests to the same L2 MAC Address it found as Source MAC in the ingressing packet. This ensures that the traffic will return using the same path without the need for an IP routing lookup to determine the next-hop to reach the originating client IP Address. Now that we are implementing a Health-Monitor mechanism we need to configure where to send traffic towards the monitoring VS that are placed outside the local network to allow the health-monitor to suceed in its role. In the diagram above, the Health-monitor will use the default-gateway 10.10.22.1 to send leaving traffic directed to other networks.

For the returning traffic, the Virtual Service just sends the traffic to the L2 observed as source in the incoming request to save IP routing lookup. There is no need to define the default gateway in the Service Engine to ensure the traffic returns using the same path.

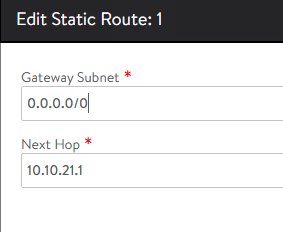
To complete the configuration go to AVI Controller at Site1 and define a Default Gateway for the Global VRF. Use 10.10.22.1 as default gateway in this case. From Infrastructure > Routing > Static Route and create a new static routing.

Repeat the process for AVI Controller at Site2 and define a Default Gateway for the Global VRF. In this case the default gateway for the selected 10.10.21.0/24 network is 10.10.21.1.
As these two services will act as followers there is no need to define anything else because the rest of the configuration and the GSLB objects will be pushed from the GSLB Leader as part of the syncing process.
Move now to the GUI at the GSLB Leader to add the two sites. Go to Infrastructure > GSLB and Add New Site. Populate the fields as shown below

Click Save and Set DNS Virtual Services

Repeat the same process for the Site2 GSLB and once completed the GSLB Configuration should display the status of the three sites. The table indicates the role, the IP address, the DNS VSes we are using for syncing the GSLB objects and the current status.

Now move to one of the follower sites and verify if the GSLB has been actually synced. Go to Applications > GSLB Services and you should be able to see any of the GSLB services that were created from AMKO in the GSLB Leader site.

If you click on the object you should get the following green icons indicating the health-monitors created by AMKO are now reaching the monitored Virtual Services.

For your information, if you had placed the Follower DNS VS in one of the existing VRFs you would get the following result. In the depicted case some of the monitors would be failing and would be marked in red color. Only the local VS will be declared as UP (green) whilst any VS outside DNS VRF will be declared as DOWN (red) due to the network connectivity issues. As you can notice
- Health-Monitor at GSLB site perceives the three VS as up. The DNS VS has been placed in the default VRF so there are no constraints.
- Health-Monitor at GSLB-Site1 site perceives only the local VRF Virtual Services as up and the external-vrf VS as declared as down.
- Similarly the Health-Monitor at GSLB-Site2 site perceives only its local VS as up the other two external VSs are not seen so they are declared as down

Having completed the setup whenever a new Ingress or LoadBalancer service is created with the appropiate label or namespace used as selector in any of the three cluster under AMKO scope, an associated GSLB service will be created by AMKO automatically in the GSLB Leader site and subsequently the AVI GSLB subsystem will be in charge of replicating this new GSLB services to other GSLB Followers to create this nice distributed system.
Configuring Zone Delegation
However, remember that we have configured the DNS to forward the queries directed to our delegated zone avi.iberia.local towards a NS that pointed only to the DNS Virtual Service at the GSLB leader site. Obviously we would need to change the current local DNS configuration to include the new DNS at Follower sites as part of the Zone Delegation.
First of all configure the DNS Service at follower sites to be authoritative for the domain avi.iberia.local to have a consistent configuration across the three DNS sites.

Set also the behaviour for Invalid DNS Query processing to send a NXDOMAIN for invalid queries.

Create an A record pointing to the follower DNS sites IP addresses.

Repeat the same process for DNS at Site2

Now click on the properties for the delegated zone

Now click Add to configure the subsequent NS entries for the our Zone Delegation setup.

Repeat the same for g-dns-site2.iberia.local virtual service and you will get this configuration

The delegated zone should display this ordered list of NS that will be used sequencially to forward the FQDN queries for the domain avi.iberia.local
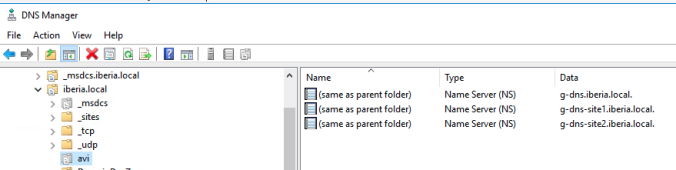
In my test the MS DNS apparently uses the NS record as they appear in the list to forward queries. In theory, the algorithm used to distribute traffic among the different NameServer entries should be Round-Robin.
# First query is sent to 10.10.24.186 (DNS VS IP @ GSLB Leader Site)
21/12/2020 9:44:39 1318 PACKET 000002DFAC51A530 UDP Rcv 192.168.170.10 12ae Q [2001 D NOERROR] A (5)hello(3)avi(6)iberia(5)local(0)
21/12/2020 9:44:39 1318 PACKET 000002DFAC1CB560 UDP Snd 10.10.24.186 83f8 Q [0000 NOERROR] A (5)hello(3)avi(6)iberia(5)local(0)
21/12/2020 9:44:39 1318 PACKET 000002DFAAF7A9D0 UDP Rcv 10.10.24.186 83f8 R Q [0084 A NOERROR] A (5)hello(3)avi(6)iberia(5)local(0)
21/12/2020 9:44:39 1318 PACKET 000002DFAC51A530 UDP Snd 192.168.170.10 12ae R Q [8081 DR NOERROR] A (5)hello(3)avi(6)iberia(5)local(0)
# Subsequent queries uses the same IP for forwarding
21/12/2020 9:44:51 1318 PACKET 000002DFAAF7A9D0 UDP Rcv 192.168.170.10 c742 Q [2001 D NOERROR] A (5)hello(3)avi(6)iberia(5)local(0)
21/12/2020 9:44:51 1318 PACKET 000002DFAC653CC0 UDP Snd 10.10.24.186 c342 Q [0000 NOERROR] A (5)hello(3)avi(6)iberia(5)local(0)
21/12/2020 9:44:51 1318 PACKET 000002DFAD114950 UDP Rcv 10.10.24.186 c342 R Q [0084 A NOERROR] A (5)hello(3)avi(6)iberia(5)local(0)
21/12/2020 9:44:51 1318 PACKET 000002DFAAF7A9D0 UDP Snd 192.168.170.10 c742 R Q [8081 DR NOERROR] A (5)hello(3)avi(6)iberia(5)local(0)Disable the DNS Virtual Service at the GSLB Leader site by clicking in the Enabled slider button on the Edit Virtual Service: g-dns window as shown below

Only after disabling the service does the local DNS try to use the second NameServer as specified in the configuration of the DNS Zone Delegation
# Query is now sent to 10.10.24.41 (DNS VS IP @ GSLB Follower Site1)
21/12/2020 9:48:56 1318 PACKET 000002DFACF571C0 UDP Rcv 192.168.170.10 4abc Q [2001 D NOERROR] A (5)hello(3)avi(6)iberia(5)local(0)
21/12/2020 9:48:56 1318 PACKET 000002DFAB203990 UDP Snd 10.10.22.40 2899 Q [0000 NOERROR] A (5)hello(3)avi(6)iberia(5)local(0)
21/12/2020 9:48:56 1318 PACKET 000002DFAAC730C0 UDP Rcv 10.10.22.40 2899 R Q [0084 A NOERROR] A (5)hello(3)avi(6)iberia(5)local(0)
21/12/2020 9:48:56 1318 PACKET 000002DFACF571C0 UDP Snd 192.168.170.10 4abc R Q [8081 DR NOERROR] A (5)hello(3)avi(6)iberia(5)local(0)Similarly do the same at site1 disabling the g-dns-site1 DNS Virtual Service

Note how the DNS is forwarding the queries to the IP Address of the DNS at site 2 (10.10.21.50) as shown below
21/12/2020 9:51:09 131C PACKET 000002DFAC927220 UDP Rcv 192.168.170.10 f6b1 Q [2001 D NOERROR] A (5)hello(3)avi(6)iberia(5)local(0)
# DNS tries to forward again to the DNS VS IP Address of the Leader
21/12/2020 9:51:09 131C PACKET 000002DFAD48F890 UDP Snd 10.10.24.186 3304 Q [0000 NOERROR] A (5)hello(3)avi(6)iberia(5)local(0)
# After timeout it fallbacks to DNS VS IP address of Site2
21/12/2020 9:51:13 0BB8 PACKET 000002DFAD48F890 UDP Snd 10.10.21.50 3304 Q [0000 NOERROR] A (5)hello(3)avi(6)iberia(5)local(0)
21/12/2020 9:51:13 131C PACKET 000002DFAAF17920 UDP Rcv 10.10.21.50 3304 R Q [0084 A NOERROR] A (5)hello(3)avi(6)iberia(5)local(0)
21/12/2020 9:51:13 131C PACKET 000002DFAC927220 UDP Snd 192.168.170.10 f6b1 R Q [8081 DR NOERROR] A (5)hello(3)avi(6)iberia(5)local(0)Datacenter blackout simulation analysis
Test 1: GSLB Leader Blackout
To verify the robustness of the architecture let’s simulate the blackout of each of the Availability Zones / DataCenter to see how the system reacts. We will now configure AMKO to split traffic evenly accross Datacenters. Edit the global-gdp object using Octant or kubectl edit command.
kubectl edit globaldeploymentpolicies.amko.vmware.com global-gdp -n avi-system
# Locate the trafficSplit section
trafficSplit:
- cluster: s1az1
weight: 5
- cluster: s1az2
weight: 5
- cluster: s2
weight: 5Remember to change the default TTL from 30 to 2 seconds to speed up the test process
while true; do curl -m 2 http://hello.avi.iberia.local -s | grep MESSAGE; sleep 2; done
# The traffic is evenly distributed accross the three k8s clusters
MESSAGE: This service resides in SITE2
MESSAGE: This Service resides in SITE2
MESSAGE: This service resides in SITE1 AZ2
MESSAGE: This service resides in SITE1 AZ2
MESSAGE: This service resides in SITE1 AZ2
MESSAGE: This service resides in SITE1 AZ1
MESSAGE: This service resides in SITE1 AZ1
MESSAGE: This service resides in SITE2
MESSAGE: This service resides in SITE1 AZ2
MESSAGE: This service resides in SITE1 AZ2
MESSAGE: This service resides in SITE1 AZ1
MESSAGE: This service resides in SITE1 AZ1
MESSAGE: This service resides in SITE1 AZ1
MESSAGE: This service resides in SITE2
MESSAGE: This service resides in SITE1 AZ2
MESSAGE: This service resides in SITE1 AZ2
MESSAGE: This service resides in SITE1 AZ1
MESSAGE: This service resides in SITE1 AZ1
MESSAGE: This service resides in SITE2
MESSAGE: This service resides in SITE2
MESSAGE: This service resides in SITE1 AZ2With this baseline now we will simulate a blackout condition in the first GSLB site as depicted in below picture:

To simulate the blackout just disconnect the AVI Controller vNICs at Site1 as well as the vNICs of the Service Engines from vCenter…

If you go to Infrastructure > GSLB, after five minutes the original GSLB Leader site appears as down with the red icon.

Also the GSLB Service hello.avi.iberia.local appear as down from the GSLB Leader site perspective as you can tell bellow.

The DataPlane yet has not been affected because the Local DNS is using the remaining NameServer entries that points to the DNS VS at Site1 and Site2 so the FQDN resolution is neither affected at all.
MESSAGE: This service resides in SITE1 AZ1
MESSAGE: This service resides in SITE2
MESSAGE: This service resides in SITE2
MESSAGE: This service resides in SITE1 AZ2
MESSAGE: This service resides in SITE1 AZ2
MESSAGE: This service resides in SITE1 AZ1
MESSAGE: This service resides in SITE1 AZ1
MESSAGE: This service resides in SITE2
MESSAGE: This service resides in SITE2Let’s create a new gslb ingress service from any of the clusters to see how this is affecting to AMKO which is in charge of sending instrucctions to the GSLB site to create the GSLB Services. I will use a new yaml file that creates the hackazon application. You can find the sample yaml file here.
kubectl apply -f hackazon_secure_ingress_gslb.yaml
deployment.apps/hackazon created
service/hackazon created
ingress.networking.k8s.io/hackazon createdThe AMKO captures this event and tries to call the API of the GSLB Leader but it is failing as you can see bellow:
kubectl logs -f amko-0 -n avi-system
E1221 18:05:50.919312 1 avisession.go:704] Failed to invoke API. Error: Post "https://10.10.20.42//api/healthmonitor": dial tcp 10.10.20.42:443: connect: no route to hostThe existing GSLB objects will remain working even when the leader is not available but the AMKO operation has been disrupted. The only way to restore the full operation is by promoting one of the follower sites to Leader. The procedure is well documented here. You would need also to change the AMKO integration settings to point to the new Leader instead of the old one.
If you restore now the connectivity to the affected site by connecting again the vNICs of both the AVI controller and the Service Engines located at GSLB Leader site, after some seconds you will see how the hackazon service is now created

You can test the hackazon application to verify not only the DNS resolution but also the datapath. Point your browser to http://hackazon.avi.iberia.local and you would get the hackazon page.

Conclusion: the GSLB Leader Site is in charge of AMKO objects realization. If we lose connectivity of this site GSLB operation will be disrupted and no more GSLB objects will be created. DataPath connectivy is not affected providing proper DNS Zone Delegation is configured at the DNS for the delegated zone. AMKO will reattempt the syncronization with the AVI controller till the Site is available. You can manually promote one of the Follower sites to Leader in order to restore full AMKO operation.
Test 2: Site2 (AKO only) Site Blackout
Now we will simulate a blackout condition in the Site2 GSLB site as depicted in below picture:

As you can imagine this condition stop connectivity to the Virtual Services at the Site2. But we need to ensure we are not sending incoming request towards this site that is now down, otherwise it might become a blackhole. The GSLB should be smart enough to detect the lost of connectivity condition and should react accordingly.
After some seconds the health-monitors declares the Virtual Services at Site2 as dead and this is reflected also in the status of the GSLB pool member for that particular site.

After some minutes the GSLB service at site 2 is also declared as down so the syncing is stopped.

The speed of the recovery of the DataPath is tied to the timers associated to health-monitors for the GSLB services that AMKO created automatically. You can explore the specific settings used by AMKO to create the Health-Monitor object by clicking the pencil next to the Health-Monitor definition in the GSLB Service you will get the following window setting

As you can see by default the Health-Monitor sends a health-check every 10 seconds. It wait up to 4 seconds to declare timeout and it waits up to 3 Failed Checks to declare the service as Down. It could take up some seconds to the full system to converge to cope with the failed site state. I have changed slightly the loop to test the traffic to do both dig resolution and a curl for getting the http server content.
while true; do dig hello.avi.iberia.local +noall +answer; curl -m 2 http://hello.avi.iberia.local -s | grep MESSAGE; sleep 1; done
# Normal behavior: Traffic is evenly distributed among the three clusters
hello.avi.iberia.local. 1 IN A 10.10.25.46
MESSAGE: This service resides in SITE1 AZ1
hello.avi.iberia.local. 0 IN A 10.10.25.46
MESSAGE: This service resides in SITE1 AZ1
hello.avi.iberia.local. 2 IN A 10.10.23.40
MESSAGE: This service resides in SITE2
hello.avi.iberia.local. 1 IN A 10.10.23.40
MESSAGE: This service resides in SITE2
hello.avi.iberia.local. 0 IN A 10.10.23.40
MESSAGE: This service resides in SITE2
hello.avi.iberia.local. 2 IN A 10.10.26.40
MESSAGE: This service resides in SITE1 AZ2
hello.avi.iberia.local. 0 IN A 10.10.26.40
MESSAGE: This service resides in SITE1 AZ2
# Blackout condition created for site 2
hello.avi.iberia.local. 0 IN A 10.10.25.46
MESSAGE: This service resides in SITE1 AZ1
hello.avi.iberia.local. 0 IN A 10.10.25.46
# DNS resolves to VS at Site 2 but no http answer is received
hello.avi.iberia.local. 0 IN A 10.10.23.40
hello.avi.iberia.local. 1 IN A 10.10.26.40
MESSAGE: This service resides in SITE1 AZ2
hello.avi.iberia.local. 0 IN A 10.10.26.40
MESSAGE: This service resides in SITE1 AZ2
hello.avi.iberia.local. 2 IN A 10.10.25.46
MESSAGE: This service resides in SITE1 AZ1
hello.avi.iberia.local. 1 IN A 10.10.25.46
MESSAGE: This service resides in SITE1 AZ1
hello.avi.iberia.local. 0 IN A 10.10.25.46
MESSAGE: This service resides in SITE1 AZ1
# Again two more times in a row DNS resolves to VS at Site 2 but no http answer again
hello.avi.iberia.local. 2 IN A 10.10.23.40
hello.avi.iberia.local. 0 IN A 10.10.23.40
# Health-Monitor has now declared Site2 VS as down. No more answers. Now traffic is distributed between the two remaining sites
MESSAGE: This service resides in SITE1 AZ2
hello.avi.iberia.local. 1 IN A 10.10.26.40
MESSAGE: This service resides in SITE1 AZ2
hello.avi.iberia.local. 0 IN A 10.10.26.40
MESSAGE: This service resides in SITE1 AZ2
hello.avi.iberia.local. 2 IN A 10.10.25.46
MESSAGE: This service resides in SITE1 AZ1
hello.avi.iberia.local. 1 IN A 10.10.25.46
MESSAGE: This service resides in SITE1 AZ1
hello.avi.iberia.local. 0 IN A 10.10.25.46Conclusion: If we lose one of the sites, the related health-monitor will declare the corresponding GSLB services as down and the DNS will stop answering with the associated IP address for the unreachable site. The recovery is fully automatic.
Test 3: Site1 AZ1 (AKO+AMKO) blackout
Now we will simulate the blackout condition of the Site1 AZ1 as depicted below

This is the cluster that owns the AMKO service so, as you can guess the DataPlane will automatically react to the disconnection of the Virtual Services at Site2. After a few seconds to allow health-monitors to declare the services as dead, you should see a traffic pattern like shown bellow in which the traffic is sent only to the available sites.
MESSAGE: This service resides in SITE1 AZ2
MESSAGE: This service resides in SITE1 AZ2
MESSAGE: This service resides in SITE1 AZ2
MESSAGE: This service resides in SITE2
MESSAGE: This service resides in SITE2
MESSAGE: This service resides in SITE2
MESSAGE: This service resides in SITE1 AZ2
MESSAGE: This service resides in SITE1 AZ2
MESSAGE: This service resides in SITE1 AZ2
MESSAGE: This service resides in SITE2
MESSAGE: This service resides in SITE2
MESSAGE: This service resides in SITE2
MESSAGE: This service resides in SITE1 AZ2
MESSAGE: This service resides in SITE1 AZ2
MESSAGE: This service resides in SITE1 AZ2
MESSAGE: This service resides in SITE2Although the DataPlane has been restored, AMKO is not available to handle the new k8s services that are created or deleted in the remaining clusters so the operation for new objects has been also disrupted. At the time of writing there isn’t any out-of-the-box mechanism to provide extra availability to cope with this specific failure and you need to design a method to ensure AMKO is restored in any of the remaining clusters. Specific Kubernetes backup solutions such as Velero can be used to backup and restore all the AMKO related objects including CRDs and secrets.
Good news is that AMKO installation is quite straighforward and is stateless so the config is very light, basically you just can reuse the original values.yaml configuration files and spin up the then AMKO in any other cluster automatically providing the prerequired secrets and connectivity are present in the cluster of the recovery site.
As a best-practique is also recommended to revoke the credentials of the affected site to avoid overlapping of two controllers in case connectivity is recovered.
Creating Custom Alarms using ControlScript
ControlScripts are Python-based scripts which execute on the Avi Vantage Controllers. They are initiated by Alert Actions, which themselves are triggered by events within the system. Rather than simply alert an admin that a specific event has occurred, the ControlScript can take specific action, such as altering the Avi Vantage configuration or sending a custom message to an external system, such as telling VMware’s vCenter to scale out more servers if the current servers have reached resource capacity and are incurring lowered health scores.
With basic knowledge of python you can create an integration with an integration with external systems. In this examplo I will create a simple that consume an external webhook running in a popular messaging service such as Slack. A webhook (aka web callback or HTTP push API) is a way for an app to provide other applications with real-time information. A webhook delivers data to other applications as it happens, meaning you get data immediately. Unlike typical APIs where you would need to poll for data very frequently in order to get it real-time. This makes webhooks much more efficient for both provider and consumer.
The first step is to create a new Incoming Webhook App from Slack. Search for Incoming Webhooks under the App catalog and just Add it.

Depending on your corporate policies you might need to request access to the administration in advance to authorize this app. Once the authorization has been complete. Personalize the Webhook as per your preferences. I am sending the messages that are sent to this Webhook to my personal Channel. The Webhook URL represents the unique URL you need to use to post messages. You can add some Description and names and even an icon to differenciate from other regular messages.

Using postman you can try to reach your Webhook just
message='{"text": "This is a sample message"}'
curl --header "Content-Type: application/json" --request POST --data "$message" https://hooks.slack.com/services/<use-your-own-webhook-here> 
That that we have learnt to send messages to Slack using a webhook method we can configure some interesting alerts related to the GSLB services we are creating to add extra customization and trigger a message to our external Slack that will act as a Pager system. Remember we are using the AVI alarm framework to create an external notification but you have the power of Python on your hand to create more sophisticated event-driven actions.
We will focus on four different key events for our example here. We want to create a notification in those cases:
- GS_MEMBER_DOWN.- Whenever a Member of the GSLB Pool is no longer available
- GS_MEMBER_UP.- Whenever a Member of the GSLB Pool is up
- GS_SERVICE_UP.- Whenever at least one of the GSLB Pool Members is up
- GS_SERVICE_DOWN.- Whenever all the GSLB Members of the pool are down
We will start with the first Alert that we will call GS_SERVICE_UP. Go to Infrastructure > Alerts > Create. Set the parameters as depicted below.

We want to capture a particular Event and we will trigger the Alert whenever the system defined alert Gs Up occurs.

When tha event occurs we will trigger an action that we have defined in advance that we have called SEND_SLACK_GS_SERVICE_UP. This Action is not populated until you created it by clicking in the pencil icon.

The Alert Action that we will call SEND_SLACK_GS_SERVICE_UP can trigger different notification to the classical management systems via email, Syslog or SNMP. We are interested here in the ControlScript section. Click on the Pencil Icon and we will create a new ControlScript that we will call SLACK_GS_SERVICE_UP.

Before tuning the message I usually create a base script that will print the arguments that are passed to the ControlScript upon triggering. To do so just configure the script with the following base code.
#!/usr/bin/python
import sys
import json
def parse_avi_params(argv):
if len(argv) != 2:
return {}
script_parms = json.loads(argv[1])
print(json.dumps(script_parms,indent=3))
return script_parms
# Main Script. (Call parse_avi_params to print the alarm contents.
if __name__ == "__main__":
script_parms = parse_avi_params(sys.argv)Now generate the Alert in the system. An easy way is to scale-in all the deployments to zero replicas to force the Health-Monitor to declare the GSLB as down and then scale-out to get the GSLB service up and running again. After some seconds the health monitor declares the Virtual Services and down and the GSLB service will appear as red.

Now scale out one of the services to at least one replica and once the first Pool member is available, the system will declare the GSLB as up (green) again.


The output of the script shown below is a JSON object that contains all the details of the event.
{ "name": "GS_SERVICE_UP-gslbservice-7dce3706-241d-4f87-86a6-7328caf648aa-1608485017.473894-1608485017-17927224", "throttle_count": 0, "level": "ALERT_LOW", "reason": "threshold_exceeded", "obj_name": "hello.avi.iberia.local", "threshold": 1, "events": [ { "event_id": "GS_UP", "event_details": { "se_hm_gs_details": { "gslb_service": "hello.avi.iberia.local" } }, "obj_uuid": "gslbservice-7dce3706-241d-4f87-86a6-7328caf648aa", "obj_name": "hello.avi.iberia.local", "report_timestamp": 1608485017 } ] }To beautify the output and to be able to understand more easily the contents of the alarm message, just paste the contents of the json object in a regular file such as /tmp/alarm.json and parse the output using jq. Now the ouput should look like this.
cat /tmp/alarm.json | jq '.'
{
"name": "GS_SERVICE_UP-gslbservice-7dce3706-241d-4f87-86a6-7328caf648aa-1608485017.473894-1608485017-17927224",
"throttle_count": 0,
"level": "ALERT_LOW",
"reason": "threshold_exceeded",
"obj_name": "hello.avi.iberia.local",
"threshold": 1,
"events": [
{
"event_id": "GS_UP",
"event_details": {
"se_hm_gs_details": {
"gslb_service": "hello.avi.iberia.local"
}
},
"obj_uuid": "gslbservice-7dce3706-241d-4f87-86a6-7328caf648aa",
"obj_name": "hello.avi.iberia.local",
"report_timestamp": 1608485017
}
]
}Now you can easily extract the contents of the alarm and create your own message. A sample complete ControlScript for this particular event is shown below including the Slack Webhook Integration.
#!/usr/bin/python
import requests
import os
import sys
import json
requests.packages.urllib3.disable_warnings()
def parse_avi_params(argv):
if len(argv) != 2:
return {}
script_parms = json.loads(argv[1])
return script_parms
# Main Script entry
if __name__ == "__main__":
script_parms = parse_avi_params(sys.argv)
gslb_service=script_parms['events'][0]['event_details']['se_hm_gs_details']['gslb_service']
message=("GS_SERVICE_UP: The service "+gslb_service+" is now up and running.")
message_slack={
"text": "Alarm Message from NSX ALB",
"color": "#00FF00",
"fields": [{
"title": "GS_SERVICE_UP",
"value": "The service *"+gslb_service+"* is now up and running."
}]}
# Display the message in the integrated AVI Alarm system
print(message)
# Set the webhook_url to the one provided by Slack when you create the
# webhook at https://my.slack.com/services/new/incoming-webhook/
webhook_url = 'https://hooks.slack.com/services/<use-your-data-here>'
response = requests.post(
webhook_url, data=json.dumps(message_slack),
headers={'Content-Type': 'application/json'}
)
if response.status_code != 200:
raise ValueError(
'Request to slack returned an error %s, the response is:\n%s'
% (response.status_code, response.text)
)Shutdown the Virtual Service by scaling-in the deployment to a number of replicas equal to zero and wait till the alarm appears

And you can see a nice formatted message in your slack app as shown below:

Do the same process for the rest of the intented alarms you want to notify using webhook and personalize your messaging extracting the required fields from the json file. For your reference you can find a copy of the four ControlScripts I have created here.
Now shutdown and reactivate the service to verify how the alarms related to the GSLB services and members of the pool appears in your Slack application as shown below.

That’s all so far regarding AMKO. Stay tuned!
