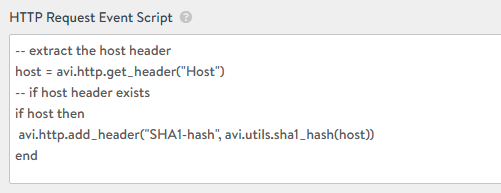
Who does not love to watch a nice dashboard full of colors? Observing patterns and real-time metrics in a time series might make us sit in front of a screen as if hypnotized for hours. But apart from the inherent beauty of dashboards, they provide observability, which is a crucial feature for understanding the performance of our applications and also a very good tool for predicting future behavior and fixing existing problems.
There is a big ecosystem out there with plenty of tools to create a logging pipeline that collect, parse, process, enrich, index, analyze and visualize logs. In this post we will focus on a combination that is gaining popularity for log Analysis that is based on FluentBit, Loki and Grafana as shown below. On the other hand we will use Prometheus for metric collection.

Let’s build the different blocks starting by the visualization tool.
Installing Grafana as visualization platform
Grafana is a free software based on Apache 2.0 license, which allows us to visualize data collected from various sources such as Prometheus, InfluxDB or Telegraph, tools that collect data from our infrastructure, such as CPU usage, memory, or network traffic of a virtual machine, a Kubernetes cluster, or each of its containers.
The real power of Grafana lies in the flexibility to create as many dashboards as we need with very smart visualization grapsh where we can format this data and represent it as we want. We will use Grafana as main tool for adding observatility capabilities to Antrea which is the purpose of this series of posts.
To carry out the installation of grafana we will rely on the official helm charts. The first step, therefore, would be to add the grafana repository so that helm can access it.
helm repo add grafana https://grafana.github.io/helm-chartsOnce the repository has been added we can broswe it. We will use the latest available release of chart to install the version 9.2.4 of Grafana.
NAME CHART VERSION APP VERSION DESCRIPTION
grafana/grafana 6.43.5 9.2.4 The leading tool for querying and visualizing t...
grafana/grafana-agent-operator 0.2.8 0.28.0 A Helm chart for Grafana Agent Operator
grafana/enterprise-logs 2.4.2 v1.5.2 Grafana Enterprise Logs
grafana/enterprise-logs-simple 1.2.1 v1.4.0 DEPRECATED Grafana Enterprise Logs (Simple Scal...
grafana/enterprise-metrics 1.9.0 v1.7.0 DEPRECATED Grafana Enterprise Metrics
grafana/fluent-bit 2.3.2 v2.1.0 Uses fluent-bit Loki go plugin for gathering lo...
grafana/loki 3.3.2 2.6.1 Helm chart for Grafana Loki in simple, scalable...
grafana/loki-canary 0.10.0 2.6.1 Helm chart for Grafana Loki Canary
grafana/loki-distributed 0.65.0 2.6.1 Helm chart for Grafana Loki in microservices mode
grafana/loki-simple-scalable 1.8.11 2.6.1 Helm chart for Grafana Loki in simple, scalable...
grafana/loki-stack 2.8.4 v2.6.1 Loki: like Prometheus, but for logs.
grafana/mimir-distributed 3.2.0 2.4.0 Grafana Mimir
grafana/mimir-openshift-experimental 2.1.0 2.0.0 Grafana Mimir on OpenShift Experiment
grafana/oncall 1.0.11 v1.0.51 Developer-friendly incident response with brill...
grafana/phlare 0.1.0 0.1.0 🔥 horizontally-scalable, highly-available, mul...
grafana/promtail 6.6.1 2.6.1 Promtail is an agent which ships the contents o...
grafana/rollout-operator 0.1.2 v0.1.1 Grafana rollout-operator
grafana/synthetic-monitoring-agent 0.1.0 v0.9.3-0-gcd7aadd Grafana's Synthetic Monitoring application. The...
grafana/tempo 0.16.3 1.5.0 Grafana Tempo Single Binary Mode
grafana/tempo-distributed 0.27.5 1.5.0 Grafana Tempo in MicroService mode
grafana/tempo-vulture 0.2.1 1.3.0 Grafana Tempo Vulture - A tool to monitor Tempo...Any helm chart includes configuration options to customize the setup by passing a configuration file that helm will use when deploying our release. We can research in the documentation to understand what all this possible helm chart values really means and how affect the final setup. Sometimes it is useful to get a file with all the default configuration values and personalize as requiered. To get the default values associated with a helm chart just use the following command.
helm show values grafana/grafana > default_values.yamlBased on the default_values.yaml we will create a customized and reduced version and we will save in a new values.yaml file with some modified values for our custom configuration. You can find the full values.yaml here. The first section enables data persistence by creating a PVC that will use the vsphere-sc storageClass we created in this previous post to leverage vSphere Container Native Storage capabilities to provision persistent volumes. Adjust the storageClassName as per your setup.
# Enable Data Persistence
persistence:
type: pvc
enabled: true
storageClassName: vsphere-sc
accessModes:
- ReadWriteOnce
size: 10GiThe second section enables the creation of sidecars containers that allow us to import grafana configurations such as datasources or dashboards through configmaps, this will be very useful to deploy Grafana fully configured in an automated way without user intervention through the graphical interface. With this settings applied, any configmap in the grafana namespace labeled with grafana_dashboard=1 will trigger the import of dashboard. Similarly, any configmaps labeled with grafana_datasource=1 will trigger the import of the grafana datasource.
# SideCars Section
# Enable Sidecars containers creationfor dashboards and datasource import via configmaps
sidecar:
dashboards:
enabled: true
label: grafana_dashboard
labelValue: "1"
datasources:
enabled: true
label: grafana_datasource
labelValue: "1"
The last section defines how to expose Grafana graphical interface externally. We will use a kubernetes service type LoadBalancer for this purpose. In my case I will use AVI as the ingress solution for our cluster so the load balancer will be created in the service engine. Feel free to use any other external LoadBalancer solution if you want.
# Define how to expose the service
service:
enabled: true
type: LoadBalancer
port: 80
targetPort: 3000
portName: serviceThe following command creates the namespace grafana and installs the grafana/grafana chart named grafana in the grafana namespace taking the values.yaml configuration file as the input. After successful deployment, the installation gives you some hints for accessing the application, e.g. how to get the credentials, which are stored in a secret k8s object. Ignore any warning about PSP you might get.
Release "grafana" has been installed. Happy Helming!
NAME: grafana
LAST DEPLOYED: Mon Dec 26 18:42:05 2022
NAMESPACE: grafana
STATUS: deployed
REVISION: 2
NOTES:
1. Get your 'admin' user password by running:
kubectl get secret --namespace grafana grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
2. The Grafana server can be accessed via port 80 on the following DNS name from within your cluster:
grafana.grafana.svc.cluster.local
Get the Grafana URL to visit by running these commands in the same shell:
export POD_NAME=$(kubectl get pods --namespace grafana -l "app.kubernetes.io/name=grafana,app.kubernetes.io/instance=grafana" -o jsonpath="{.items[0].metadata.name}")
kubectl --namespace grafana port-forward $POD_NAME 3000
3. Login with the password from step 1 and the username: adminAs explained in the notes after helm installation, the first step is to get the plaintext password that will be used to authenticate the default admin username in the Grafana UI.
wFCT81uGC7ij5Sv1rTIuf2CwQa5Y9xkGQSixDKOxVeryfing Grafana Installation
Before moving to the Grafana UI let’s explore created kubernetes resources and their status.
NAME READY STATUS RESTARTS AGE
pod/grafana-7d95c6cf8c-pg5dw 3/3 Running 0 24m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/grafana LoadBalancer 10.100.220.164 10.113.3.106 80:32643/TCP 24m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/grafana 1/1 1 1 24m
NAME DESIRED CURRENT READY AGE
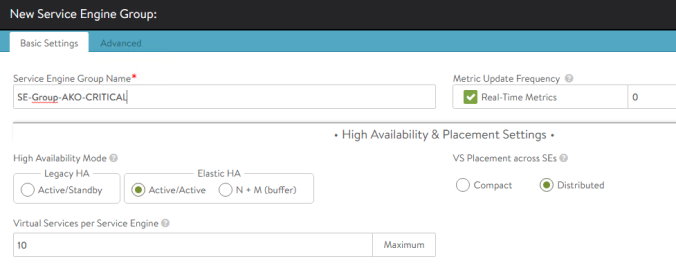
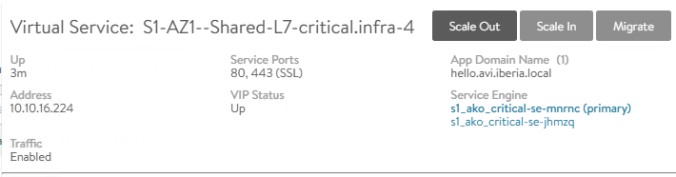
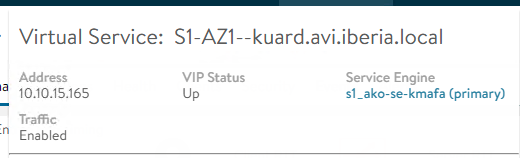
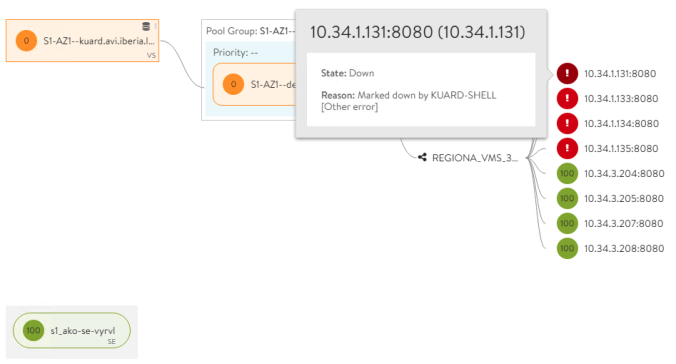
replicaset.apps/grafana-7d95c6cf8c 1 1 1 24mThe chart has created a deployment with 3 grafana replica pods that are in running status. Note how the LoadBalancer service has already allocated the external IP address 10.113.3.106 to provide outside reachability. As mentioned earlier, if you have a LoadBalancer solution such as AVI with his AKO operator deployed in your setup you will see that a new Virtual Service has been created and it’s ready to use as shown below:

Now you can open your browser and type the IP Address. AVI also register in its internal DNS the new LoadBalancer objects that the developer creates in kubernetes. In this specific setup an automatic FQDN is created and grafana should be available from your browser at http://grafana.grafana.avi.sdefinitive.net. As specified in the LoadBalancer section in the values.yaml at deployment type, the grafana GUI will be exposed on port 80. For security purpose is strongly recommended to use a Secure Ingress object instead if you are planning to deploy in production.

This way we would have finished the installation of Grafana visualization tool. Let’s move now to install another important piece in observability in charge of retrieving metrics which is Prometheus.
Prometheus for metric collection
Prometheus was created to monitor highly dynamic environments, so over the past years it has become the mainstream monitoring tool of choice in container and microservices world. Modern devops is becoming more and more complex to handle manually and there is a need for automation. Imagine a complex infrastructure with loads of servers distributed over many locations and you have no insight of what is happening in terms of errors, latency, usage and so on. In a modern architecture there are more things than can go wrong when you have tons of dynamic and ephemeral services and applications and any of them can crash and cause failure of other services. This is why is crucial to avoid manual intervention and allow the administrator to quickly identify and fix any potential problem or degradation of the system.
The prometheus architecture is represented in the following picture that has been taken from the official prometheus.io website.

The heart componentes of the prometheus server are listed below
- Data Retrieval Worker.- responsible for fetching time series data from a particular data source, such as a web server or a database, and converting it into the Prometheus metric format.
- Time Series Data Base (TSDB).- used to store, manage, and query time-series data.
- HTTP Server.- responsible for exposing the Prometheus metrics endpoint, which provides access to the collected metrics data for monitoring and alerting purposes.
The first step would be enabling Prometheus
Installing Prometheus
Prometheus requires access to Kubernetes API resources for service discovery, access to the Antrea Metrics Listener and some configuration to instruct the Data Retrieval Worker to scrape the required metrics in both Agent and Controller components. There are some manifests in the Antrea website ready to use to save some time with all the scraping and job configurations of Prometheus. Lets apply the provided manifest as a first step.
namespace/monitoring created
serviceaccount/prometheus created
secret/prometheus-service-account-token created
clusterrole.rbac.authorization.k8s.io/prometheus created
clusterrolebinding.rbac.authorization.k8s.io/prometheus created
configmap/prometheus-server-conf created
deployment.apps/prometheus-deployment created
service/prometheus-service createAs you can see in the output the manifest include all required kubernetes objects including permissions, configurations and lastly the prometheus server itself. The manifest deploy all the resources in a dedicated monitoring namespace.
NAME READY STATUS RESTARTS AGE
pod/prometheus-deployment-57d7b4c6bc-jx28z 1/1 Running 0 42s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/prometheus-service NodePort 10.101.177.47 <none> 8080:30000/TCP 42s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/prometheus-deployment 1/1 1 1 42s
NAME DESIRED CURRENT READY AGE
replicaset.apps/prometheus-deployment-57d7b4c6bc 1 1 1 42sFeel free to explore all created resources. As you can tell there is a new service is running as a NodePort type so you should be able to reach the Prometheus server using any of your workers IP addresses that listen at the static 30000 port. Alternatively you can always use port-forward method to redirect a local port to the service listening at 8080. Open a browser to verify you can access to the HTTP Server component of Prometheus.

Prometheus configuration will retrieve not only Antrea related metrics but also some built in kubernetes metrics. Just for fun type “api” in the search box and you will see dozens of metrics available.

Now we are sure Prometheus Server is running and is able to scrape metrics succesfully, lets move into our area of interest that is Antrea CNI.
Enabling Prometheus Metrics in Antrea
The first step is to configure Antrea to generate Prometheus metrics. As we explain in the previous post here we are using Helm to install Antrea so the better way to change the configuration of the Antrea setup is by using the values.yaml file and redeploying the helem chart. As you can see we are enabling also the FlowExporter featuregate. This is a mandatory setting to allow conntrack flows related metrics to get updated. Edit the values.yaml
# -- Container image to use for Antrea components.
image:
tag: "v1.10.0"
enablePrometheusMetrics: true
featureGates:
FlowExporter: true
AntreaProxy: true
TraceFlow: true
NodePortLocal: true
Egress: true
AntreaPolicy: trueDeploy a new release of antrea helm chart taking the values.yaml file as in input. Since the chart is already deployed, now we need to use upgrade keyword instead of install as did the first time.
Release "antrea" has been upgraded. Happy Helming!
NAME: antrea
LAST DEPLOYED: Wed Jan 18 13:53:56 2023
NAMESPACE: kube-system
STATUS: deployed
REVISION: 2
TEST SUITE: None
NOTES:
The Antrea CNI has been successfully installed
You are using version 1.10.0
For the Antrea documentation, please visit https://antrea.ioNow with antctl command verify the feature gates has been enabled as expected
Antrea Agent Feature Gates
FEATUREGATE STATUS VERSION
Traceflow Enabled BETA
AntreaIPAM Disabled ALPHA
Multicast Disabled ALPHA
AntreaProxy Enabled BETA
Egress Enabled BETA
EndpointSlice Disabled ALPHA
ServiceExternalIP Disabled ALPHA
AntreaPolicy Enabled BETA
Multicluster Disabled ALPHA
FlowExporter Enabled ALPHA
NetworkPolicyStats Enabled BETA
NodePortLocal Enabled BETA
Antrea Controller Feature Gates
FEATUREGATE STATUS VERSION
AntreaPolicy Enabled BETA
NetworkPolicyStats Enabled BETA
NodeIPAM Disabled ALPHA
Multicluster Disabled ALPHA
Egress Enabled BETA
Traceflow Enabled BETA
ServiceExternalIP Disabled ALPHA As seen before Prometheus has some built-in capabilities to browse and visualize metrics however we want this metric to be consumed from the powerful Grafana that we have installed earlier. Lets access to the Grafana console and click on the Gear icon to add the new Prometheus Datasource.

Grafana has been deployed in the same cluster in a different namespace. The prometheus URL is derived from <service>.<namespace>.svc.<port>.domain. In our case the URL is http://prometheus-service.monitoring.svc:8080. If your accessing Prometheus from a different cluster ensure you use the FQDN adding the corresponding domain at the end of the URL (by default cluster.local).

Click on Save & Test blue button at the bottom of the screen and you should see a message indicating the Prometheus server is reachable and working as expected.

Now click on the compass button to verify that Antrea metrics are being populated and are reachable from Grafana for visualization. Select new added Prometheus as Datasource at the top.

Pick up any of the available antrea agent metrics (I am using here antrea_agent_local_pod_count as an example) and you should see the visualization of the gathered metric values in the graph below.

That means Prometheus datasource is working and Antrea is populating metrics successfully. Let’s move now into the next piece Loki.
Installing Loki as log aggregator platform
In the last years the area of log management has been clearly dominated by the Elastic stack becoming the de-facto standard whereas Grafana has maintained a strong position in terms of visualization of metrics from multiple data sources, among which prometheus stands out.
Lately a very popular alternative for log management is Grafana Loki. The Grafana Labs website describes Loki as a horizontally scalable, highly available, multi-tenant log aggregation system inspired by Prometheus. It is designed to be very cost effective and easy to operate. It does not index the contents of the logs, but rather a set of labels for each log stream.
For that reason we will use Loki as a solution for aggregating the logs we got from kubernetes pods. We will focus on Antrea related pods but it can be used with a wider scope for the rest of applications ruunning in your cluster.
In the same way that we did in the Grafana installation, we will use the official helm chart of the product to proceed with the installation. This time it is not necessary to install a new helm repository because the Loki chart is already included in the grafana repo. As we did with Grafana helm chart, the first step will be to obtain the configuration file associated to the helm chart that we will use to be able to customize our installation.
helm show values grafana/loki > default_values.yamlUsing this file as a reference, create a reduced and customized values.yaml file with some modified configuration. As a reminder, any setting not explicitly mentioned in the reduced values.yaml file will take the default values. Find the values.yaml file I am using here.
For a production solution it is highly recommended to install Loki using the scalable architecture. The scalable architecture requires a managed object store such as AWS S3 or Google Cloud Storage but, if you are planning to use it on-premises, a very good choice is to use a self-hosted store solution such as the popular MinIO. There is a previous post explaining how to deploy a a MinIO based S3-like storage platform based on vSAN here. In case you are going with MinIO Operator, as a prerequisite before installing Loki, you would need to perform following tasks.
The following script will
- Create a new MinIO tenant. We will use a new tenant called logs in the namespace logs.
- Obtain the S3 endpoint that will be used to interact with your S3 storage via API. I am using here the internal ClusterIP endpoint but feel free to use the external FQDN if you want to expose it externally. In that case you would use the built-in kubernetes naming convention for pods and services as explained here and, that it would be something like minio.logs.svc.cluster.local.
- Obtain the AccessKey and SecretAccessKey. By default a set of credentials are generated upon tenant creation. You can extract them from the corresponding secrets easily or just create a new set of credentials using Minio Tenant Console GUI.
- Create the required buckets. You can use console or mc tool as well.
Considering you are using MinIO operator, the following script will create required tenant and buckets. Copy and Paste the contents in the console or create a sh file and execute it using bash. Adjust the tenant settings in terms of servers, drives and capacity match with your environment. All the tenant objects will be placed in the namespace logs.
#!/bin/bash
TENANT=logs
BUCKET1=chunks
BUCKET2=ruler
BUCKET3=admin
# CREATE NAMESPACE AND TENANT 6 x 4 drives for raw 50 G, use Storage Class SNA
# -------------------------------------------------------------------------------
kubectl create ns $TENANT
kubectl minio tenant create $TENANT --servers 6 --volumes 24 --capacity 50G --namespace $TENANT --storage-class vsphere-sna --expose-minio-service --expose-console-service
# EXTRACT CREDENTIALS FROM CURRENT TENANT AND CREATE SECRET
# ---------------------------------------------------------
echo "MINIO_S3_ENDPOINT=https://minio.${TENANT}.svc.cluster.local" > s3vars.env
echo "MINIO_S3_BUCKET1=${BUCKET1}" >> s3vars.env
echo "MINIO_S3_BUCKET2=${BUCKET2}" >> s3vars.env
echo "MINIO_S3_BUCKET3=${BUCKET3}" >> s3vars.env
echo "SECRET_KEY=$(kubectl get secrets -n ${TENANT} ${TENANT}-user-1 -o jsonpath="{.data.CONSOLE_SECRET_KEY}" | base64 -d)" >> s3vars.env
echo "ACCESS_KEY=$(kubectl get secrets -n ${TENANT} ${TENANT}-user-1 -o jsonpath="{.data.CONSOLE_ACCESS_KEY}" | base64 -d)" >> s3vars.env
kubectl create secret generic -n $TENANT loki-s3-credentials --from-env-file=s3vars.envOnce the tenant is created we can proceed with bucket creation. You can do it manually via console or mc client or using following yaml file used to define a job that will create the required buckets as shown here. Basically it will wait untill the tenant is initialized and then it will created the three required buckets as per the secret loki-s3-credentials injected variables.
apiVersion: batch/v1
kind: Job
metadata:
name: create-loki-minio-buckets
namespace: logs
spec:
template:
spec:
containers:
- name: mc
# loki-s3-credentials contains $ACCESS_KEY, $SECRET_KEY, $MINIO_S3_ENDPOINT, $MINIO_S3_BUCKET1-3
envFrom:
- secretRef:
name: loki-s3-credentials
image: minio/mc
command:
- sh
- -c
- ls /tmp/error > /dev/null 2>&1 ; until [[ "$?" == "0" ]]; do sleep 5; echo "Attempt to connect with MinIO failed. Attempt to reconnect in 5 secs"; mc alias set s3 $(MINIO_S3_ENDPOINT) $(ACCESS_KEY) $(SECRET_KEY) --insecure; done && mc mb s3/$(MINIO_S3_BUCKET1) --insecure; mc mb s3/$(MINIO_S3_BUCKET2) --insecure; mc mb s3/$(MINIO_S3_BUCKET3) --insecure
restartPolicy: Never
backoffLimit: 4Verify job execution is completed displaying the logs created by the pod in charge of completing the defined job.
mc: <ERROR> Unable to initialize new alias from the provided credentials. The Access Key Id you provided does not exist in our records.
Attempt to connect with MinIO failed. Attempt to reconnect in 5 secs
Added `s3` successfully.
Bucket created successfully `s3/chunks`.
Bucket created successfully `s3/ruler`.
Bucket created successfully `s3/admin`.Now the S3 storage requirement is fullfiled. Lets move into the values.yaml file that will be used as the configuration source for our Loki deployment. The first section provides some general configuration options including the data required to access the shared S3 store. Replace s3 attributes with your particular settings.
loki:
auth_enabled: false
storage_config:
boltdb_shipper:
active_index_directory: /var/loki/index
cache_location: /var/loki/index_cache
resync_interval: 5s
shared_store: s3
compactor:
working_directory: /var/loki/compactor
shared_store: s3
compaction_interval: 5m
storage:
bucketNames:
chunks: chunks
ruler: ruler
admin: admin
type: s3
s3:
s3:
endpoint: https://minio.logs.svc.cluster.local:443
region: null
secretAccessKey: YDLEu99wPXmAAFyQcMzDwDNDwzF32GnS8HhHBuoD
accessKeyId: ZKYLET51JWZ8LXYYJ0XP
s3ForcePathStyle: true
insecure: true
#
querier:
max_concurrent: 4096
#
query_scheduler:
max_outstanding_requests_per_tenant: 4096
# Configuration for the write
# <continue below...>Note. If you used the instructions above to create the MinIO Tenant you can extract the S3 information from the plaintext s3vars.env variable. You can also extract from the secret logs-user-1. Remember to delete the s3vars.env file after usage as it may reveal sensitive information.
MINIO_S3_ENDPOINT=https://minio.logs.svc.cluster.local
MINIO_S3_BUCKET1=chunks
MINIO_S3_BUCKET2=ruler
MINIO_S3_BUCKET3=admin
SECRET_KEY=YDLEu99wPXmAAFyQcMzDwDNDwzF32GnS8HhHBuoD
ACCESS_KEY=ZKYLET51JWZ8LXYYJ0XPWhen object storage is configured, the helm chart configures Loki to deploy read and write targets in high-availability fashion running 3 replicas of each independent process. It will use a storageClass able to provide persistent volumes to avoid losing data in case of the failure of the application. Again, I am using here a storage class called vsphere-sc that is backed by vSAN and accesed by a CSI driver. If you want to learn how to provide data persistence using vSphere and vSAN check a previous post here.
# Configuration for the write
write:
persistence:
# -- Size of persistent disk
size: 10Gi
storageClass: vsphere-sc
# Configuration for the read node(s)
read:
persistence:
# -- Size of persistent disk
size: 10Gi
storageClass: vsphere-sc
# -- Selector for persistent disk
# Configuration for the Gateway
# <continue below..>Additionally, the chart installs the gateway component which is an NGINX that exposes Loki’s API and automatically proxies requests to the correct Loki components (read or write in our scalable setup). If you want to reach Loki from the outside (e.g. other clusters) you must expose it using any kubernetes methods to gain external reachability. In this example I am using a LoadBalancer but feel free to explore further options in the defaults_values.yaml such as a secure Ingress. Remember when the gateway is enabled, the visualization tool (Grafana) as well as the log shipping agents (Fluent-Bit) should be configured to use the gateway as endpoint.
# Configuration for the Gateway
gateway:
# -- Specifies whether the gateway should be enabled
enabled: true
# -- Number of replicas for the gateway
service:
# -- Port of the gateway service
port: 80
# -- Type of the gateway service
type: LoadBalancer
# Basic auth configuration
basicAuth:
# -- Enables basic authentication for the gateway
enabled: false
# -- The basic auth username for the gateway
The default chart will install another complementary components in Loki called canary and backend. Loki canary component is fully described here. Basically it is used to audit the log-capturing performance of Loki by generating artificial log lines.
Once the values.yaml file is completed we can proceed with the installation of the helm chart using following command. I am installing loki in the a namespace named loki.
Release "loki" has been installed. Happy Helming!
NAME: loki
LAST DEPLOYED: Wed Feb 14 12:18:46 2023
NAMESPACE: loki
STATUS: deployed
REVISION: 1
NOTES:
***********************************************************************
Welcome to Grafana Loki
Chart version: 4.4.1
Loki version: 2.7.2
***********************************************************************
Installed components:
* grafana-agent-operator
* gateway
* read
* write
* backendNow we are done with Loki installation in a scalable and distributed architecture and backed by a MinIO S3 storage, let’s do some verifications to check everything is running as expected.
Verifying Loki Installation
As a first step, explore the kubernetes objects that the loki chart has created.
NAME READY STATUS RESTARTS AGE
pod/loki-backend-0 1/1 Running 0 2m13s
pod/loki-backend-1 1/1 Running 0 2m49s
pod/loki-backend-2 1/1 Running 0 3m37s
pod/loki-canary-4xkfw 1/1 Running 0 5h42m
pod/loki-canary-crxwt 1/1 Running 0 5h42m
pod/loki-canary-mq79f 1/1 Running 0 5h42m
pod/loki-canary-r76pz 1/1 Running 0 5h42m
pod/loki-canary-rclhj 1/1 Running 0 5h42m
pod/loki-canary-t55zt 1/1 Running 0 5h42m
pod/loki-gateway-574476d678-vkqc7 1/1 Running 0 5h42m
pod/loki-grafana-agent-operator-5555fc45d8-rcs59 1/1 Running 0 5h42m
pod/loki-logs-25hvr 2/2 Running 0 5h42m
pod/loki-logs-6rnmt 2/2 Running 0 5h42m
pod/loki-logs-72c2w 2/2 Running 0 5h42m
pod/loki-logs-dcwkb 2/2 Running 0 5h42m
pod/loki-logs-j6plp 2/2 Running 0 5h42m
pod/loki-logs-vgqqb 2/2 Running 0 5h42m
pod/loki-read-598f8c5cd5-dqtqt 1/1 Running 0 2m59s
pod/loki-read-598f8c5cd5-fv6jq 1/1 Running 0 2m18s
pod/loki-read-598f8c5cd5-khmzw 1/1 Running 0 3m39s
pod/loki-write-0 1/1 Running 0 93s
pod/loki-write-1 1/1 Running 0 2m28s
pod/loki-write-2 1/1 Running 0 3m33s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/loki-backend ClusterIP 10.98.167.78 <none> 3100/TCP,9095/TCP 5h42m
service/loki-backend-headless ClusterIP None <none> 3100/TCP,9095/TCP 5h42m
service/loki-canary ClusterIP 10.97.139.4 <none> 3500/TCP 5h42m
service/loki-gateway LoadBalancer 10.111.235.35 10.113.3.104 80:30251/TCP 5h42m
service/loki-memberlist ClusterIP None <none> 7946/TCP 5h42m
service/loki-read ClusterIP 10.99.220.81 <none> 3100/TCP,9095/TCP 5h42m
service/loki-read-headless ClusterIP None <none> 3100/TCP,9095/TCP 5h42m
service/loki-write ClusterIP 10.102.132.138 <none> 3100/TCP,9095/TCP 5h42m
service/loki-write-headless ClusterIP None <none> 3100/TCP,9095/TCP 5h42m
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/loki-canary 6 6 6 6 6 <none> 5h42m
daemonset.apps/loki-logs 6 6 6 6 6 <none> 5h42m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/loki-gateway 1/1 1 1 5h42m
deployment.apps/loki-grafana-agent-operator 1/1 1 1 5h42m
deployment.apps/loki-read 3/3 3 3 5h42m
NAME DESIRED CURRENT READY AGE
replicaset.apps/loki-gateway-574476d678 1 1 1 5h42m
replicaset.apps/loki-grafana-agent-operator-5555fc45d8 1 1 1 5h42m
replicaset.apps/loki-read-598f8c5cd5 3 3 3 3m40s
replicaset.apps/loki-read-669c9d7689 0 0 0 5h42m
replicaset.apps/loki-read-6c7586fdc7 0 0 0 11m
NAME READY AGE
statefulset.apps/loki-backend 3/3 5h42m
statefulset.apps/loki-write 3/3 5h42mNAME A simple test you can do to verify gateway status is by “curling” the API endpoint exposed in the allocated external IP. The OK response would indicate the service is up and ready to receive requests.
OKNow access grafana console and try to add Loki as a DataSource. Click on the Engine button at the bottom of the left bar and then click on Add Data Source blue box.

Click on Loki to add the required datasource type.

In this setup Grafana and Loki has been deployed in the same cluster so we can use as URL the internal FQDN corresponding to the loki-gateway ClusterIP service. In case you are accesing from the outside you need to change that to the external URL (e.g. http://loki-gateway.loki.avi.sdefinitive.net in my case).

Click on “Save & test” button and if the attempt of Grafana to reach Loki API endpoint is successful, it should display the green tick as shown below.

Another interesting verification would be to check if the MinIO S3 bucket is getting the logs as expected. Open the MinIO web console and access to the chunks bucket wich is the target to write the logs Loki receives. You should see how the bucket is receiving new objects and how the size is increasing.

You may wonder who is sending this data to Loki at this point since we have not setup any log shipper yet. The reason behind is that, by default, when you deploy Loki using the official chart, a sub-chart with Grafana Agent is also installed to enable self monitoring. Self monitoring settings determine whether Loki should scrape it’s own logs. It will create custom resources to define how to scrape it’s own logs. If you are curious about it explore (i.e kubectl get) GrafanaAgent, LogsInstance, and PodLogs CRDs objects created in the Loki namespace to figure out how this is actually pushing self-monitoring logs into Loki.
To verify what are this data being pushed into MinIO S3 bucket, you can explore Loki Datasource through Grafana. Return to the Grafana GUI and try to show logs related to a loki component such as the loki-gateway pod. Click on the compass icon at the left to explore the added datasource. Now filter using job as key label and select the name of the loki/loki-gateway as value label as shown below. Click on Run Query blue button on the top right corner next to see what happens.

Et voila! If everything is ok you should see how logs are successfully being shipped to Loki by its internal self monitoring Grafana agent.

Now that our log aggregator seems to be ready let’s move into the log shipper section.
Installing Fluent-Bit
Fluent-Bit is an log shipper based in a open source software designed to cover highly distributed environments that demand high performance but keeping a very light footprint.
The main task of Fluent-bit in this setup is watch for changes in any interesting log file and send any update in that file to Loki in a form of a new entry. We will focus on Antrea related logs only so far but you can extend the input of Fluent-bit to a wider scope in order to track other logs of your OS.
Again we will rely in helm to proceed with the installation. This time we need to add a new repository maintaned by fluent.
helm repo add fluent https://fluent.github.io/helm-chartsExplore the repo to see what is.
NAME CHART VERSION APP VERSION DESCRIPTION
fluent/fluent-bit 0.22.0 2.0.8 Fast and lightweight log processor and forwarde...
fluent/fluentd 0.3.9 v1.14.6 A Helm chart for Kubernetes As we did before, create a reference yaml file with default configuration values of the chart.
helm show values fluent/fluent-bit > default_values.yamlUsing default_values.yaml as a template, create a new values.yaml file that will contain the desired configuration. The main piece of the values.yaml file resides on the config section. You can customize how the logs will be treated in a secuencial fashion creating a data pipeline scheme as depicted here.

The full documentation is maintained in the Fluent-Bit website here, but in a nutshell the main subsections we will use to achieve our goal are:
- SERVICE.- The service section defines global properties of the service, including additional parsers to adapt the data found in the logs.
- INPUT.- The input section defines a source that is associated to an input plugin. Depending on the selected input plugin you will have extra configuration keys. In this case we are using the tail input plugin that capture any new line of the watched files (Antrea logs in this case). This section is also used to tag the captured data for classification purposes in later stages.
- PARSER.- This section is used to format or parse any information present on records such as extracting fields according to the position of the information in the log record.
- FILTER.- The filter section defines a filter that is associated with a filter plugin. In this case we will use the kubernetes filter to be able enrich our log files with Kubernetes metadata.
- OUTPUT.- The output section section specify a destination that certain records should follow after a Tag match. We would use here Loki as target.
We will use following values.yaml file. A more complex values file including parsing and regex can be found in an specific section of the next post here.
env:
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
config:
service: |
[SERVICE]
Daemon Off
Flush {{ .Values.flush }}
Log_Level {{ .Values.logLevel }}
Parsers_File parsers.conf
Parsers_File custom_parsers.conf
HTTP_Server On
HTTP_Listen 0.0.0.0
HTTP_Port {{ .Values.metricsPort }}
Health_Check On
## https://docs.fluentbit.io/manual/pipeline/inputs
inputs: |
[INPUT]
Name tail
Path /var/log/containers/antrea*.log
multiline.parser docker, cri
Tag antrea.*
Mem_Buf_Limit 5MB
Skip_Long_Lines On
## https://docs.fluentbit.io/manual/pipeline/filters
## First filter Uses a kubernetes filter plugin. Match antrea tag. Use K8s Parser
## Second filter enriches log entries with hostname and node name
filters: |
[FILTER]
Name kubernetes
Match antrea.*
Merge_Log On
Keep_Log Off
K8S-Logging.Parser On
K8S-Logging.Exclude On
[FILTER]
Name record_modifier
Match antrea.*
Record podname ${HOSTNAME}
Record nodename ${NODE_NAME}
## https://docs.fluentbit.io/manual/pipeline/outputs
## Send the matching data to loki adding a label
outputs: |
[OUTPUT]
Name loki
Match antrea.*
Host loki-gateway.loki.svc
Port 80
Labels job=fluentbit-antreaCreate the namespace fluent-bit where all the objects will be placed.
kubectl create ns fluent-bitAnd now proceed with fluent-bit chart installation.
NAME: fluent-bit
LAST DEPLOYED: Wed Jan 11 19:21:20 2023
NAMESPACE: fluent-bit
STATUS: deployed
REVISION: 1
NOTES:
Get Fluent Bit build information by running these commands:
export POD_NAME=$(kubectl get pods --namespace fluent-bit -l "app.kubernetes.io/name=fluent-bit,app.kubernetes.io/instance=fluent-bit" -o jsonpath="{.items[0].metadata.name}")
kubectl --namespace fluent-bit port-forward $POD_NAME 2020:2020
curl http://127.0.0.1:2020Verifying Fluent-Bit installation
As suggested by the highlighted output of the previous chart installlation you can easily try to reach the fluent-bit API that is listening at port TCP 2020 using a port-forward. Issue the port-forward action and try to curl to see if the service is accepting the GET request. The output indicates the service is ready and you get some metadata such as flags, and version associated with the running fluent-bit pod.
jhasensio@forty-two:~/ANTREA$ curl localhost:2020 -s | jq
{
"fluent-bit": {
"version": "2.0.8",
"edition": "Community",
"flags": [
"FLB_HAVE_IN_STORAGE_BACKLOG",
"FLB_HAVE_CHUNK_TRACE",
"FLB_HAVE_PARSER",
"FLB_HAVE_RECORD_ACCESSOR",
"FLB_HAVE_STREAM_PROCESSOR",
"FLB_HAVE_TLS",
"FLB_HAVE_OPENSSL",
"FLB_HAVE_METRICS",
"FLB_HAVE_WASM",
"FLB_HAVE_AWS",
"FLB_HAVE_AWS_CREDENTIAL_PROCESS",
"FLB_HAVE_SIGNV4",
"FLB_HAVE_SQLDB",
"FLB_LOG_NO_CONTROL_CHARS",
"FLB_HAVE_METRICS",
"FLB_HAVE_HTTP_SERVER",
"FLB_HAVE_SYSTEMD",
"FLB_HAVE_FORK",
"FLB_HAVE_TIMESPEC_GET",
"FLB_HAVE_GMTOFF",
"FLB_HAVE_UNIX_SOCKET",
"FLB_HAVE_LIBYAML",
"FLB_HAVE_ATTRIBUTE_ALLOC_SIZE",
"FLB_HAVE_PROXY_GO",
"FLB_HAVE_JEMALLOC",
"FLB_HAVE_LIBBACKTRACE",
"FLB_HAVE_REGEX",
"FLB_HAVE_UTF8_ENCODER",
"FLB_HAVE_LUAJIT",
"FLB_HAVE_C_TLS",
"FLB_HAVE_ACCEPT4",
"FLB_HAVE_INOTIFY",
"FLB_HAVE_GETENTROPY",
"FLB_HAVE_GETENTROPY_SYS_RANDOM"
]
}
}Remember the fluent-bit process needs access to the logs that are generated on every single node, that means you will need daemonSet object that will run a local fluent-bit pod in each of the eligible nodes across the cluster.
NAME READY STATUS RESTARTS AGE
pod/fluent-bit-8s72h 1/1 Running 0 9m20s
pod/fluent-bit-lwjrn 1/1 Running 0 9m20s
pod/fluent-bit-ql5gp 1/1 Running 0 9m20s
pod/fluent-bit-wkgnh 1/1 Running 0 9m20s
pod/fluent-bit-xcpn9 1/1 Running 0 9m20s
pod/fluent-bit-xk7vc 1/1 Running 0 9m20s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/fluent-bit ClusterIP 10.111.248.240 <none> 2020/TCP 9m20s
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/fluent-bit 6 6 6 6 6 <none> 9m20sYou can also display the logs that any of the pods generates on booting. Note how the tail input plugin only watches matching files according to the regex (any file with name matching antrea*.log in /var/log/containers/ folder).
Fluent Bit v2.0.8
* Copyright (C) 2015-2022 The Fluent Bit Authors
* Fluent Bit is a CNCF sub-project under the umbrella of Fluentd
* https://fluentbit.io
[2023/01/11 18:21:32] [ info] [fluent bit] version=2.0.8, commit=9444fdc5ee, pid=1
[2023/01/11 18:21:32] [ info] [storage] ver=1.4.0, type=memory, sync=normal, checksum=off, max_chunks_up=128
[2023/01/11 18:21:32] [ info] [cmetrics] version=0.5.8
[2023/01/11 18:21:32] [ info] [ctraces ] version=0.2.7
[2023/01/11 18:21:32] [ info] [input:tail:tail.0] initializing
[2023/01/11 18:21:32] [ info] [input:tail:tail.0] storage_strategy='memory' (memory only)
[2023/01/11 18:21:32] [ info] [input:tail:tail.0] multiline core started
[2023/01/11 18:21:32] [ info] [filter:kubernetes:kubernetes.0] https=1 host=kubernetes.default.svc port=443
[2023/01/11 18:21:32] [ info] [filter:kubernetes:kubernetes.0] token updated
[2023/01/11 18:21:32] [ info] [filter:kubernetes:kubernetes.0] local POD info OK
[2023/01/11 18:21:32] [ info] [filter:kubernetes:kubernetes.0] testing connectivity with API server...
[2023/01/11 18:21:32] [ info] [filter:kubernetes:kubernetes.0] connectivity OK
[2023/01/11 18:21:32] [ info] [output:loki:loki.0] configured, hostname=loki-gateway.loki.svc:80
[2023/01/11 18:21:32] [ info] [http_server] listen iface=0.0.0.0 tcp_port=2020
[2023/01/11 18:21:32] [ info] [sp] stream processor started
[2023/01/11 18:21:32] [ info] [input:tail:tail.0] inotify_fs_add(): inode=529048 watch_fd=1 name=/var/log/containers/antrea-agent-b4tfl_kube-system_antrea-agent-9dadd3c909f9471408ebf569c0d8f2622bedd572ef7a982bfe71a7f3cd6010d0.log
[2023/01/11 18:21:32] [ info] [input:tail:tail.0] inotify_fs_add(): inode=532180 watch_fd=2 name=/var/log/containers/antrea-agent-b4tfl_kube-system_antrea-agent-fd6cfdb5a18c77e66403e66e3a16e2f577d213cd010bdf09f863e22d897194a8.log
[2023/01/11 18:21:32] [ info] [input:tail:tail.0] inotify_fs_add(): inode=532181 watch_fd=3 name=/var/log/containers/antrea-agent-b4tfl_kube-system_antrea-ovs-5344c17989a14d5773ae75e4403c12939c34b2ca53fb5a09951d8fd953cea00d.log
[2023/01/11 18:21:32] [ info] [input:tail:tail.0] inotify_fs_add(): inode=529094 watch_fd=4 name=/var/log/containers/antrea-agent-b4tfl_kube-system_antrea-ovs-cb343ab16cc1d9a718b938be8a889196fd93134f63c9f9da6c53a2ff291f25f5.log
[2023/01/11 18:21:32] [ info] [input:tail:tail.0] inotify_fs_add(): inode=528986 watch_fd=5 name=/var/log/containers/antrea-agent-b4tfl_kube-system_install-cni-583b2d7380e3dc9cff9c3a05870c7997747d9751c075707bd182d1d0a0ec5e9b.logNow we are sure the fluent-bit is working properly, the last step is to check if we actually are receiving the logs in Loki using Grafana to retrieve ingested logs. Remember in the fluent-bit output configuration we labeled the logs using job=fluentbit-antrea and we will use that as input to filter our interesting logs. Click on the compass icon at the left ribbon and use populate the label filter with mentioned label (key and value).

Generate some activity in the antrea agents, for example, as soon as you create a new pod and the CNI should provide the IP Address and it will write a corresponding log indicating a new IP address has been Allocated. Let’s try to locate this exact string in any antrea log. To do so, just press on the Code button, to write down a custom filter by hand.

Type the following filter to find any log with a label job=fluentbit-antrea that also contains the string “Allocated”.
{job="fluentbit-antrea"} |= "Allocated" Press Run Query blue button at the right top corner and you should be able to display any matching log entry as shown below.

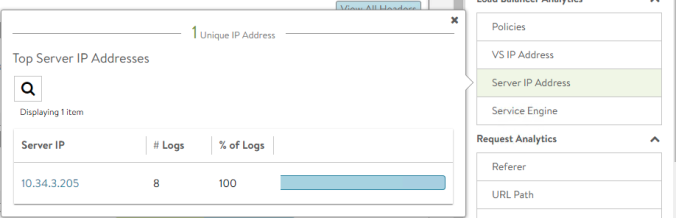
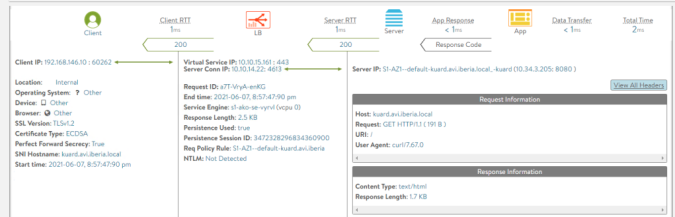
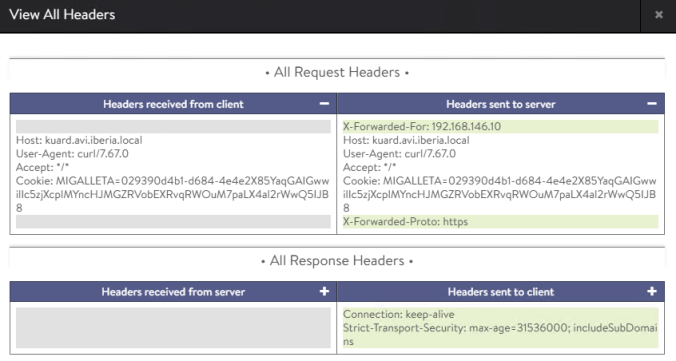
Feel feel to explore further the log to see the format and different labels and fields as shown below

This concludes this post. If you followed it you should now have the required tools up and running to gain observability. This is just the first step though. For any given observability solution, the real effort come in the Day 2 when you need to figure out what are your KPI according to your particular needs and how to visualize them in the proper way. Next post here will continue diving in dashboards and log analysis. Stay tuned!